
This page introduces and describes some tools and methods for performing searches in corpora.
Table of contents
1 Regular expressions
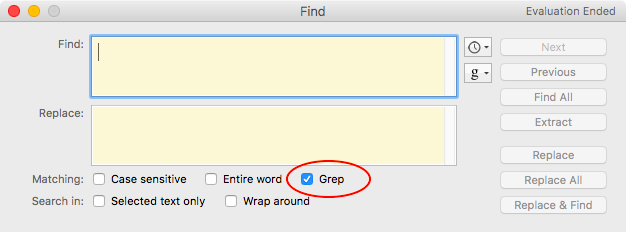
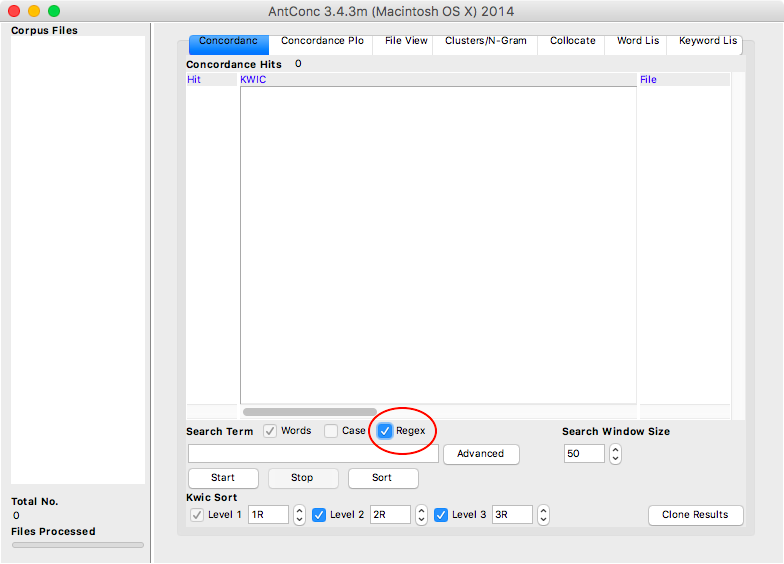
Regular expressions (abbreviated as regex, sometimes referred to as grep) are sequences of special characters that allow the formulation of comprehensive search queries in a text or a collection of texts. Regular expressions are a standard that can be used in many text editors (see Figure 1), search tools (see Figure 2), and programming languages. As such, regular expressions are not a search tool per se, but rather a query syntax employed by numerous search tools.
1.1 Wild cards
One function of regular expressions is the use of Wild Card Characters, i.e. characters that allow a portion of the query to remain unspecified. The most general wild card is the character . (period/full stop), which matches any character in a given line, be it a letter, number, space, or punctuation mark. For example, the search term n.t will not only match words such as net, not or nut, but also sequences such as n t, n't, n0t. In addition to the general . wild card, more specific wild cards can be used, such as \w, which will match word characters only, i.e. letters, numbers, and underscores, but not spaces and punctuation. For example, the search term n\wt will match nit, not, nut, n0t, or n_t, but not n t or n't. An overview of wild cards is given in Table 1.
| Wild card | Coverage | Example query | Example matches |
|---|---|---|---|
. |
Any character except line breaks | n.t |
nut, n0t, n t, n't |
\w |
Word character (letters, digits, underscore) | n\wt |
nut, n0t, n_t |
\W |
NOT a word character | n\Wt |
n t, n't |
\d |
Digit (0-9) | n\dt |
n0t, n9t |
\D |
NOT a digit | n\Dt |
nut, n t, n_t, n't |
\s |
Whitespace (space, tab, line break) | n\st |
n t |
\S |
NOT whitespace | n\St |
nut, n0t, n_t, n't |
\b |
Word boundary | \bone |
one, oneself |
\B |
NOT a word boundary | \Bone |
bone, none |
When searching for the actual characters used as wild cards (or any special characters for that matter), these characters need to be escaped. For example, when searching for the sequences etc. or what?, using these as search terms would mean “etc followed by any character” or “wha which may or may not be followed by a t”, respectively. Escaping a special character is done via a \ (backslash), as in etc\. or what\?. In such instances, . and ? match the actual character and do not act as wild cards.
It should also be noted that the specification of word boundaries with \b may not be necessary for text editors or corpus tools that have an Entire word or Words checkbox (see Figures 1 and 2).
1.2 Quantifiers
In addition to wild cards, regular expressions also make use of Quantifiers, which specify how often a given character or character sequence should occur. For example, if one were to search for forms of the verb to feed, the search term fe+d would match fed and feed, as the + quantifier means that the preceding character should occur “one or more times”. Quantifiers can be combined with wild cards, so that the search term f.+d means “f followed by any characters repeated one or more times, followed by a d”, and therefore matches fed and feed as before, but also food, feud, find, or for a pound.
It is important to note that by default, quantifiers are greedy, which means that they will attempt to find the largest possible match. In a line such as “I found a pound on the ground yesterday”, the search term f.+d does not stop the match at the first d encountered, but rather expands it to the largest possible match, i.e. the last d in the line, hence the match found a pound on the ground yesterd. In order to make quantifiers lazy, i.e. limit the results to the smallest possible match, add a ? (question mark) after the quantifier. In our example line “I found a pound on the ground yesterday”, the search term f.+?d matches found only.
Please note that the ? character has two functions: it can act as a quantifier of its own, meaning “once or none”, and it can determine lazy quantifier behavior when placed after a quantifier. An overview of quantifiers is given in Table 2.
| Quantifier | Repetitions | Example query | Example matches |
|---|---|---|---|
+ |
Once or more | fe+d |
fed, feed |
* |
Zero or more | t.*o |
to, two, trio |
? |
Zero or one | fiancee? |
fiance, fiancee |
{n} |
Exactly n times | b.{2}t |
boot, boat, beat, bent |
{m,n} |
Between m and n times | t.{2,4}t |
that, treat, threat |
{n,} |
n times or more | t.{3,}t |
treat, threat, the very best |
1.3 Character classes
Queries can be even more fine-grained with the definition of Character Classes, which can be used in cases where the default wild cards do not exactly match the desired pattern. For example, if the goal is to find sequences of vowels surrounded by b and t, the search terms b.+t or b\w+t are not adequate as they match unwanted sequences such as bent or brought. To remedy this, a character class of vowels can be defined in [ ] (square brackets), so that the search term b[aeiou]+t matches bat, bet, bit, but, beat, beet, boat, boot, bout, etc., but excludes any sequences that contain a consonant in the central portion of the sequence.
Further, entire character ranges can be defined. For example, if one wishes to search for word characters without digits or underscores, a character class consisting of only letters of the Latin alphabet can be defined with the range [a-z], so that the search term n[a-z]t matches net, not, and nut, but not n_t or n0t. Assuming that the search is Case Sensitive, the range [a-z] includes only lower case letters. To include upper case letters, the range should be extended to [a-zA-Z]. Many text editors offer a check box to toggle between case sensitive and case insensitive searching (see Figures 1 and 2). If case sensitive searching is turned off, the range [a-z] will suffice to cover the entire Latin alphabet. An overview of character classes is given in Table 3.
| Character class | Range | Example query | Example matches |
|---|---|---|---|
[a] |
One of the characters in the brackets | b[aeiou]t |
bat, bet, bit, bot, but |
[a-b] |
One of the characters in the range from a to b |
[A-Za-z]at |
Bat, bat, Cat, cat, Oat, oat, Rat, rat |
[^a] |
A character that is NOT a |
[^c]at |
Bat bat, Cat, Oat, oat, Rat, rat |
[^a-b] |
A character that is NOT in the range from a to b |
[^A-Ca-c]at |
Oat, oat, Rat, rat |
1.4 Grouping
Regular expressions allow the definition of Groups, i.e. sequences of characters that should be treated as a unit. This is achieved by enclosing the sequence in ( ) (parentheses). For example, defining the character sequence un as a group allows a search for the words happy and unhappy with a single search term by applying a quantifier to the group as a whole rather than to its individual characters, as in (un)?happy.
Once defined, a group is assigned a running number, a process known as Catching, and placing a \ before this number accesses the contents of the group. If, for example, one were to search for words that begin and end with the same letter, the search term \b(\w)\w*\1\b would achieve this by defining a word character at the beginning of a word as group 1, and finding the same word character, now accessible as \1, at the end of the same word, as in that, sometimes, or extreme. More than one group can be defined per search term. For example, the search term \b(\w)(\w)\w*\2\1\b finds words that begin with a sequence of two letters (the first letter being defined as group 1, the second letter as group 2) and end with the reversed sequence (groups 2 and 1), as in level or reader.
1.5 Logical operators
Logical Operators are words or symbols that allow the formulation of Boolean Expressions, i.e. expressions that can be evaluated as either True or False (which in turn are called Boolean Values). The main logical operators are AND (∧), OR (∨), and NOT (¬). NOT has already been implicitly addressed in the discussion of wild cards, where the use of an upper case letter inverts the value of the lower case alternative (e.g. \W meaning “NOT a word character” as opposed to \w meaning “word character”, see Table 1), and character classes, where the use of ^ signals the exclusion rather than the inclusion of a character or character range (see Table 3).
It should be noted that the logical operator OR functions differently from the conjunction or used in everyday language, which frequently means “one or the other, but not both”, and is therefore closer to the “exclusive or” XOR (⊻) logical operator. In contrast, OR means “either, but also both”. In regular expressions, the OR operator is represented by the | (pipe) character. A search term such as apple|pear|kiwi returns apple, pear, and kiwi as matches.
1.6 Combining groups and logical operators
When used within groups, the OR operator provides more flexible search capabilities than character classes. For example, in a search for words derived with the prefixes {un-} and {in-} (including its allomorphs {{il-, im-, ir-}}), the use of character classes would require two distinct searches, i.e. \bun\w+ and \bi[lmnr]\w+, or a single search term \b[iu][lmnr]\w+ that would match unwanted word-initial sequences such as ul in ultimate, um in umbrella, or ur in urban. Instead, using \b(un|il|im|in|ir)\w+ matches only the desired word-initial sequences. In other words, character classes offer character alternations within a single slot, whereas the combination of groups and the OR operator enables alternations of larger character patterns. The search term can be shortened by using character classes within a group, as in \b(un|i[lmnr])\w+. The behavior of groups and the logical operator OR is summarized in Table 4.
| Pattern | Function | Example query | Example matches |
|---|---|---|---|
a|b|c |
Either character sequence separated by | |
this|that|these|those |
this, that, these, those |
(abc) |
Character sequence enclosed in ( ) is treated as a group |
historic(al)? |
historic, historical |
(ab)\1 |
Group content is accessible via its running number | (\w)o\1 |
mom, pop, wow |
a(b|c)d |
Alternation applies within the group only | Ind(i|ian|onesi)a |
India, Indiana, Indonesia |
1.7 Exercises
You can practice the use of regular expressions by doing the exercises below. I recommend you actually perform the queries rather than just answer the questions in your head. To do so, download a text editor such as Atom, Notepad++, or BBEdit, and some sample texts, for example free e-books from the Gutenberg Project or the Internet Archive.
How would you search a text for words that rhyme with the word magical?
Defining rhyme as the nucleus and coda of a syllable, any word ending with the sequence al is a likely candidate for a rhyme, such as natural, eternal, etc. Simply searching for the sequence al is not sufficient, as this will include words such as aluminium or California. To ensure that the al sequence is at the end of a word, it should be specified that it precedes a word boundary, i.e. al\b. There are further character sequences that correspond to the phonological sequence /(ǝ)l/, as in the words travel or circle. The regular expression can therefore be made more comprehensive by including these, i.e. (al|el|le)\b. However, this will also return unwanted matches such as feel, file, rule, etc.
How would you search a text for adjectives that are formed with the prefix {un-} and the suffix {-able}, such as unbelievable or untenable?
Words beginning with un can be found by placing a word boundary before the prefix, so \bun. Words ending with able can be found by placing a word boundary after the suffix, so able\b. The unspecified root to which the affixes attach can be defined by using quantifier + (“one or more”) with the wild card \w. The quantifier * (“zero or more”) is inadequate, as this would include the word unable. The final search term is therefore \bun\w+able\b.
How would you search the spelling variations of composer Georg Friedrich Händel’s surname (Händel, Haendel, Handel) with a single search term? There are multiple correct ways of achieving this.
The search term H(a|ae|ä)ndel will find all three spelling variants. The search term can be slightly shortened with the use of quantifiers, as in H(ae?|ä)ndel.
1.8 Further reading
This tutorial has only covered some basics of searching with regular expressions. However, regular expressions are far more powerful and also allow text transformations, such as substitutions. The resources below can serve as references to learn more about regular expressions.
The website RexEgg.com provides detailed information, tutorials, and cheat sheets on regular expressions.
For even more detailed introductions, some introductory and reference books on regular expressions are available, such as Fitzgerald (2012), Goyvaerts & Levithan (2012), or Stubblebine (2007).
2 AntConc
AntConc (Anthony, 2023) is a popular freeware corpus analysis toolkit for concordancing and text analysis. The toolkit is available for Windows, macOS, and Linux, and features tools (accessible via buttons at the top of the program window) that facilitate queries in plain-text and POS-annotated corpora without requiring any programming knowledge. Some of AntConc’s tools are introduced below. AntConc uses a Corpus Manager to open and organize corpus files. The option File > Open File(s) as 'Quick Corpus'... allows you to select one or more files to be loaded, whereas the option File > Open Corpus Manager... gives access to a multi-purpose tool that can load and save pre-built corpora, or create and save new corpora from raw files. For the purpose of this introduction, the option File > Open File(s) as Quick Corpus... will suffice to load individual files.
2.1 Concordance
A Concordance is a corpus query undertaken to obtain the frequency of a search term and to verify in which contexts it occurs. An example using AntConc's KWIC tool is shown in Figure 3.
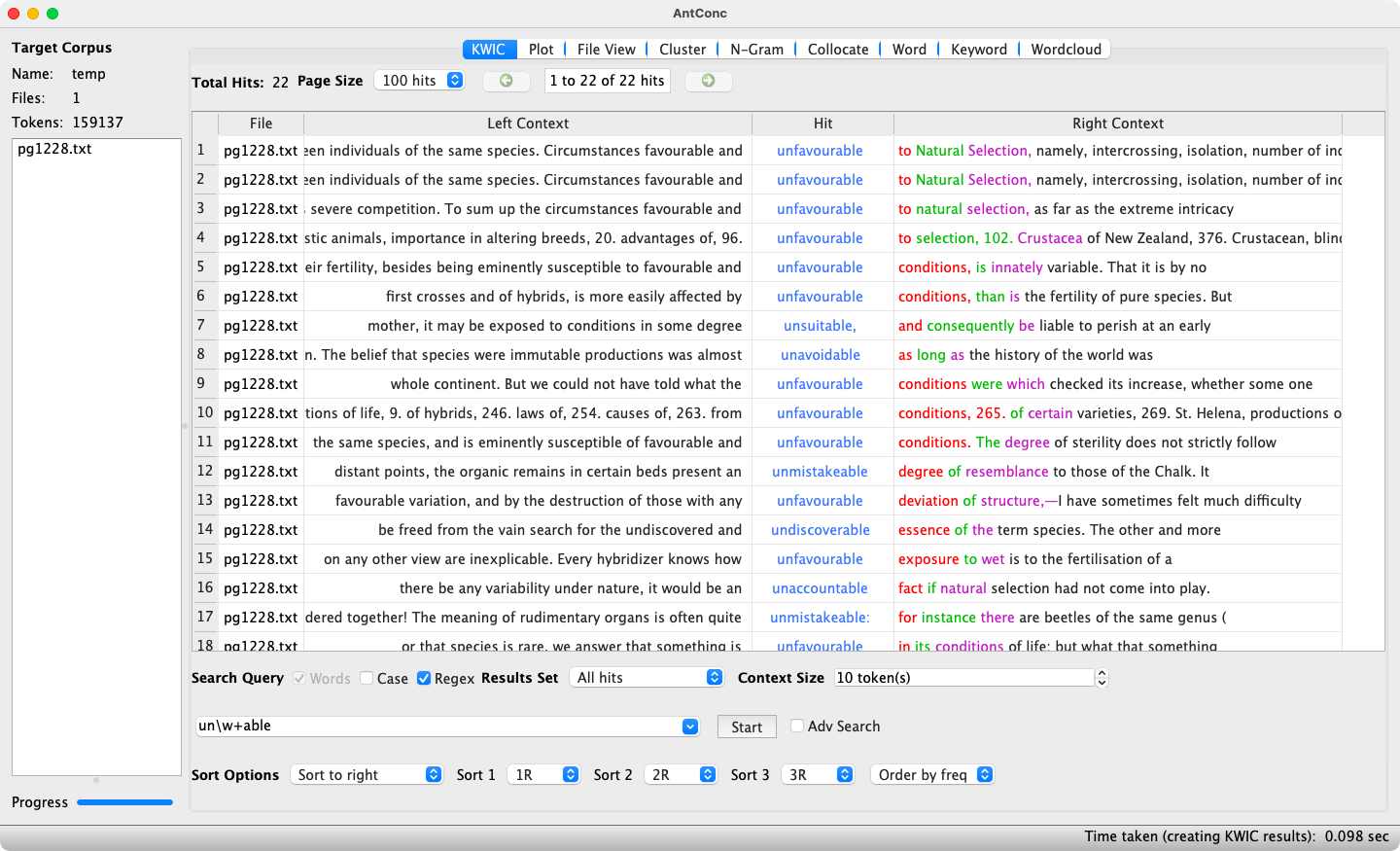
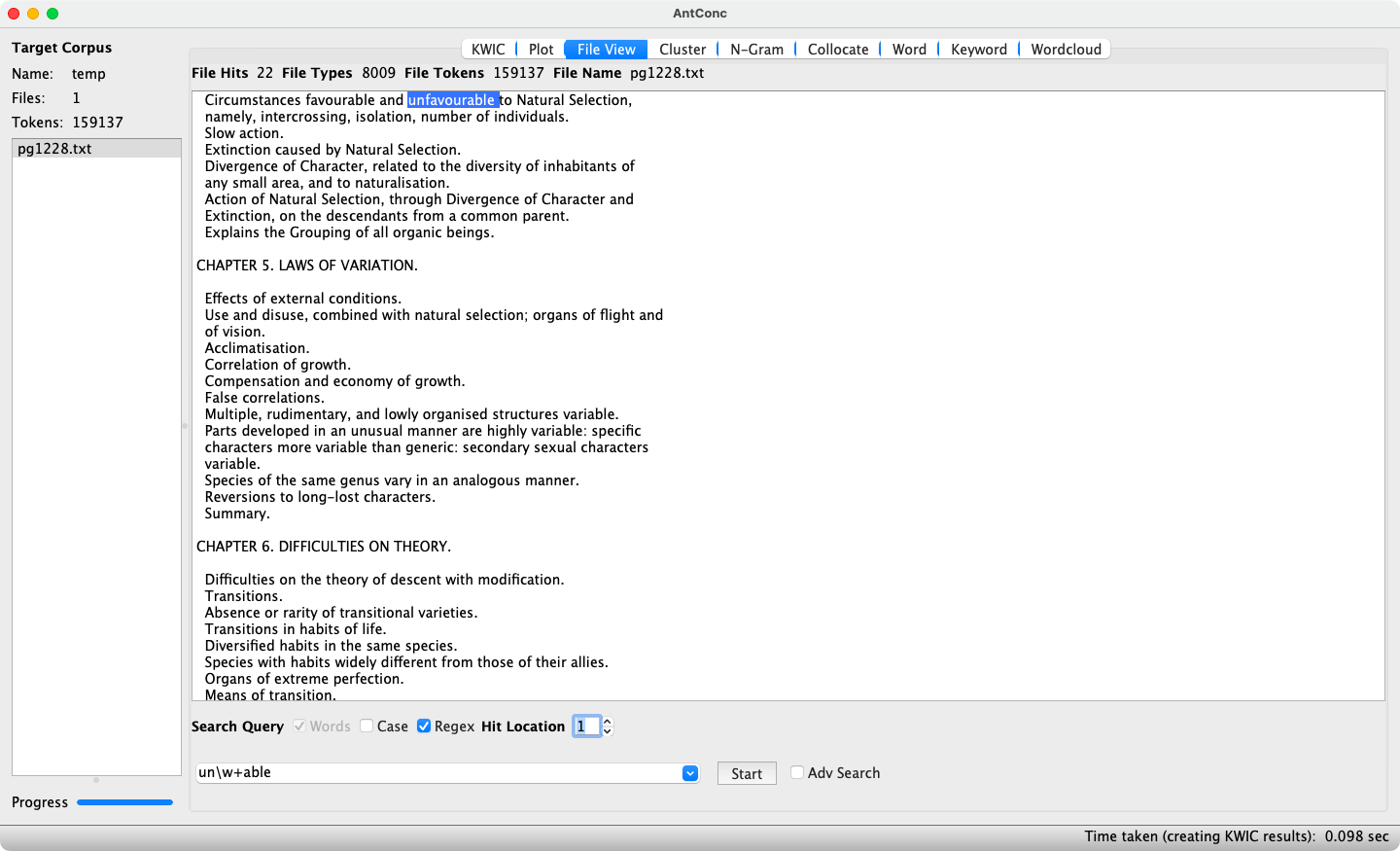
The search term used employs regular expressions as well as the Words mode, so that word boundaries do not have to be additionally specified. The results display the frequency of the search term (22), as well as a KeyWord In Context view (shortened to KWIC). In KWIC, each hit is shown on a separate line and highlighted in blue, surrounded by its immediate context. Keywords can be sorted using the drop-down menus at the bottom of the window according to the nth element to the left (nL) or right (nR) to see whether certain contexts are recurrent. Double-clicking on a highlighted keyword switches to the File View tool (see Figure 4), where a larger context for the hit is displayed. A return to the KWIC view is achieved by clicking the KWIC button.
2.2 Concordance plot
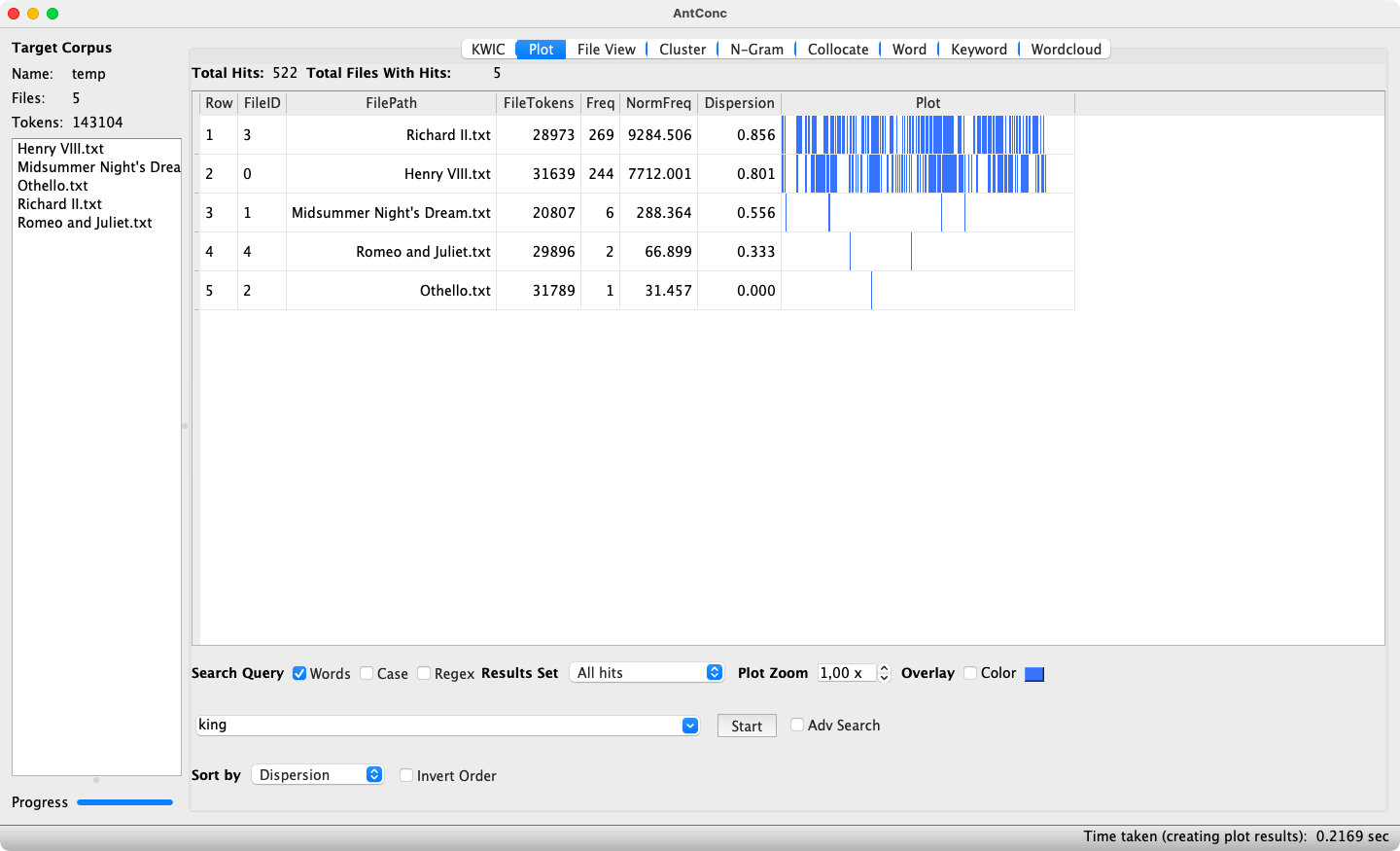
AntConc’s Concordance Plot tool displays the results of a concordance query in a different manner. Each hit is shown as a thin blue line within a larger rectangle, which in turn represents the entire text. Thus, the relative position of each hit within the text can be visualized, which enables the detection of any “hot spots”. Further, a concordance plot involving multiple texts reveals whether different texts exhibit varying frequencies of the searched item. An example concordance plot is shown in Figure 5.
2.3 Clusters/N-Grams
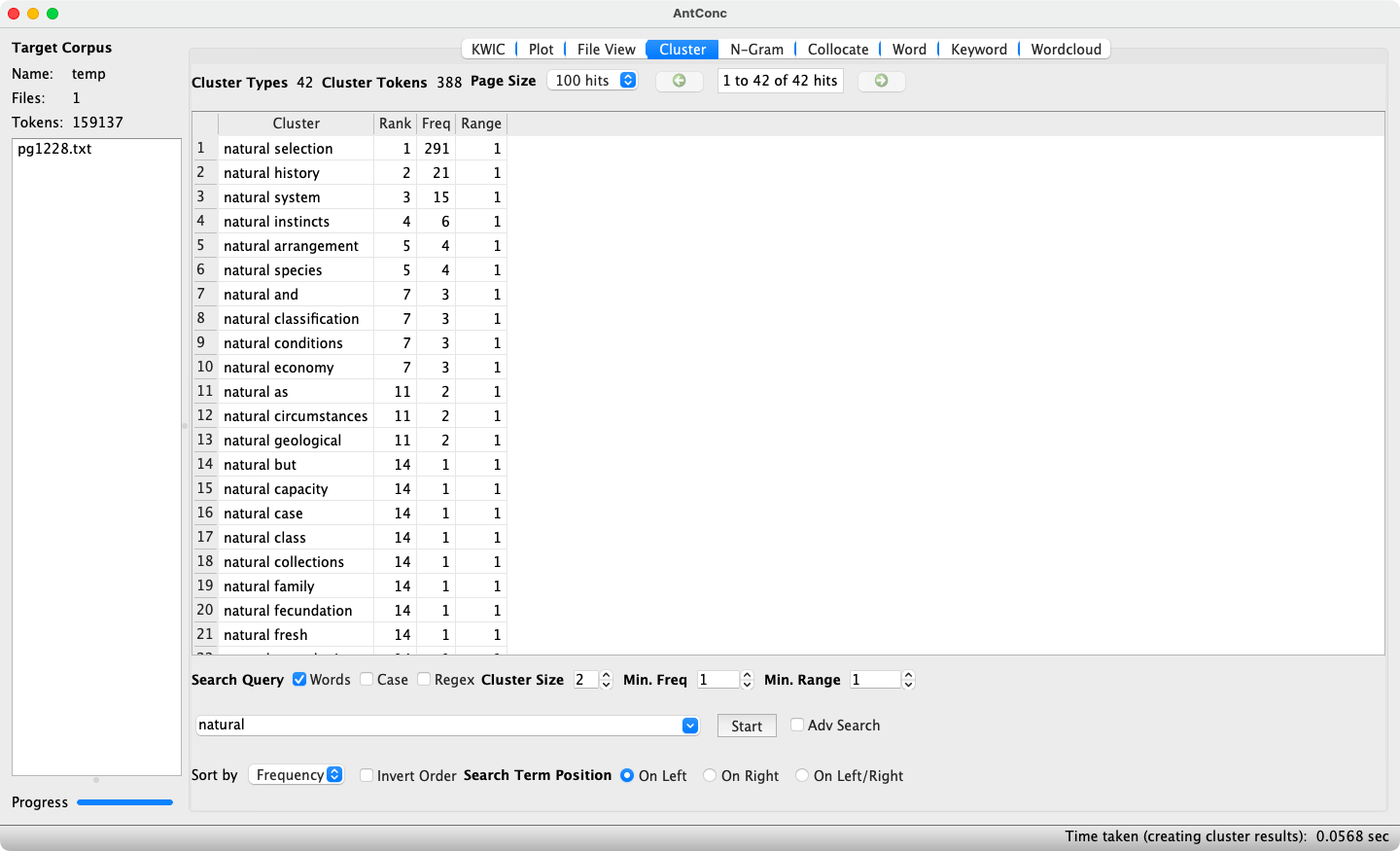
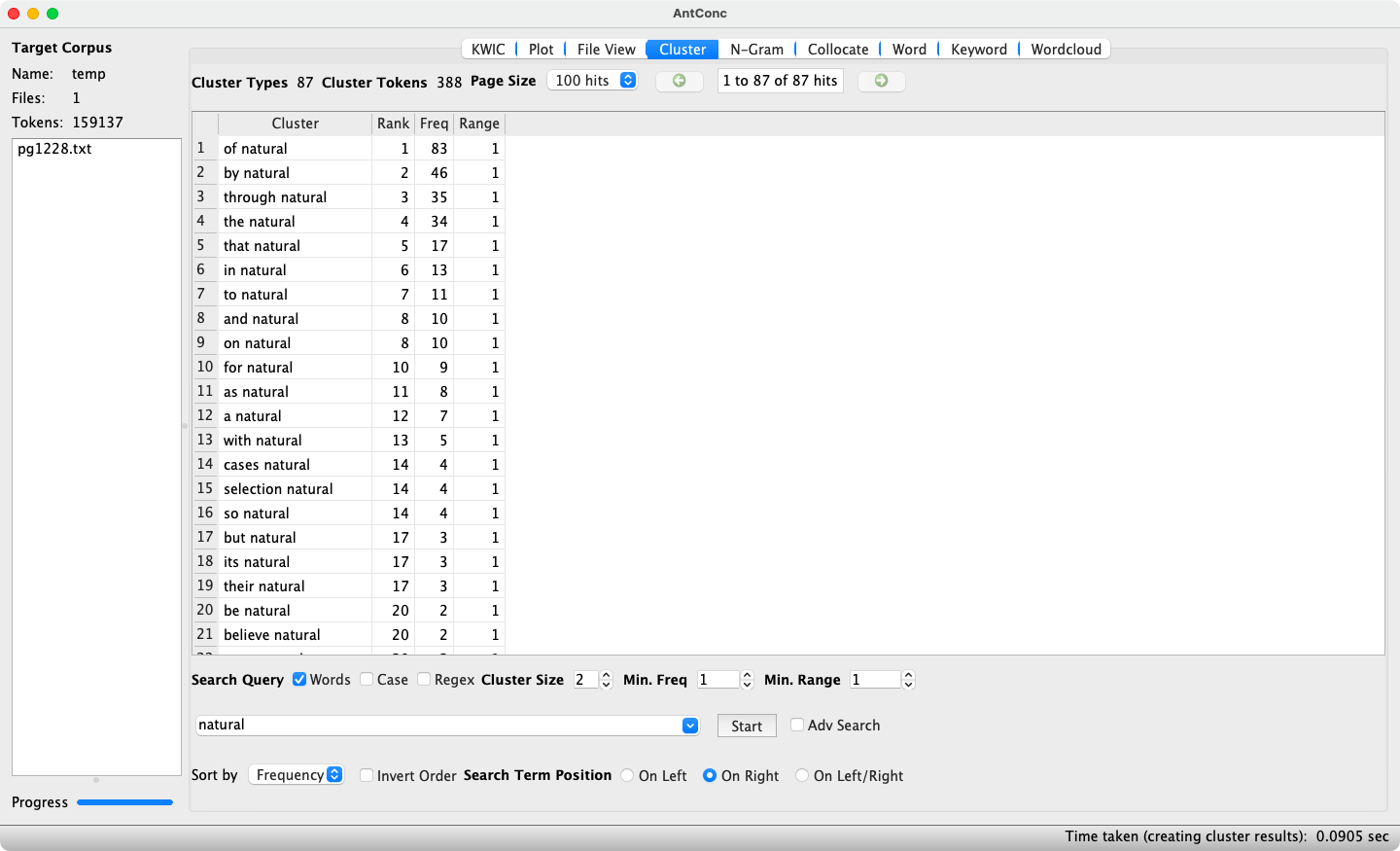
AntConc’s Cluster tool identifies which words frequently co-occur with a specified search term. Clusters can be specified with the search term to the left (see Figure 6) or to the right (see Figure 7). The minimum and maximum cluster size can be defined, as well as the minimum frequency, which when set to 2 ensures that only re-occurring clusters are displayed. Double-clicking on a cluster switches to the KWIC tool, where individual instances of the cluster are shown in a KWIC view.
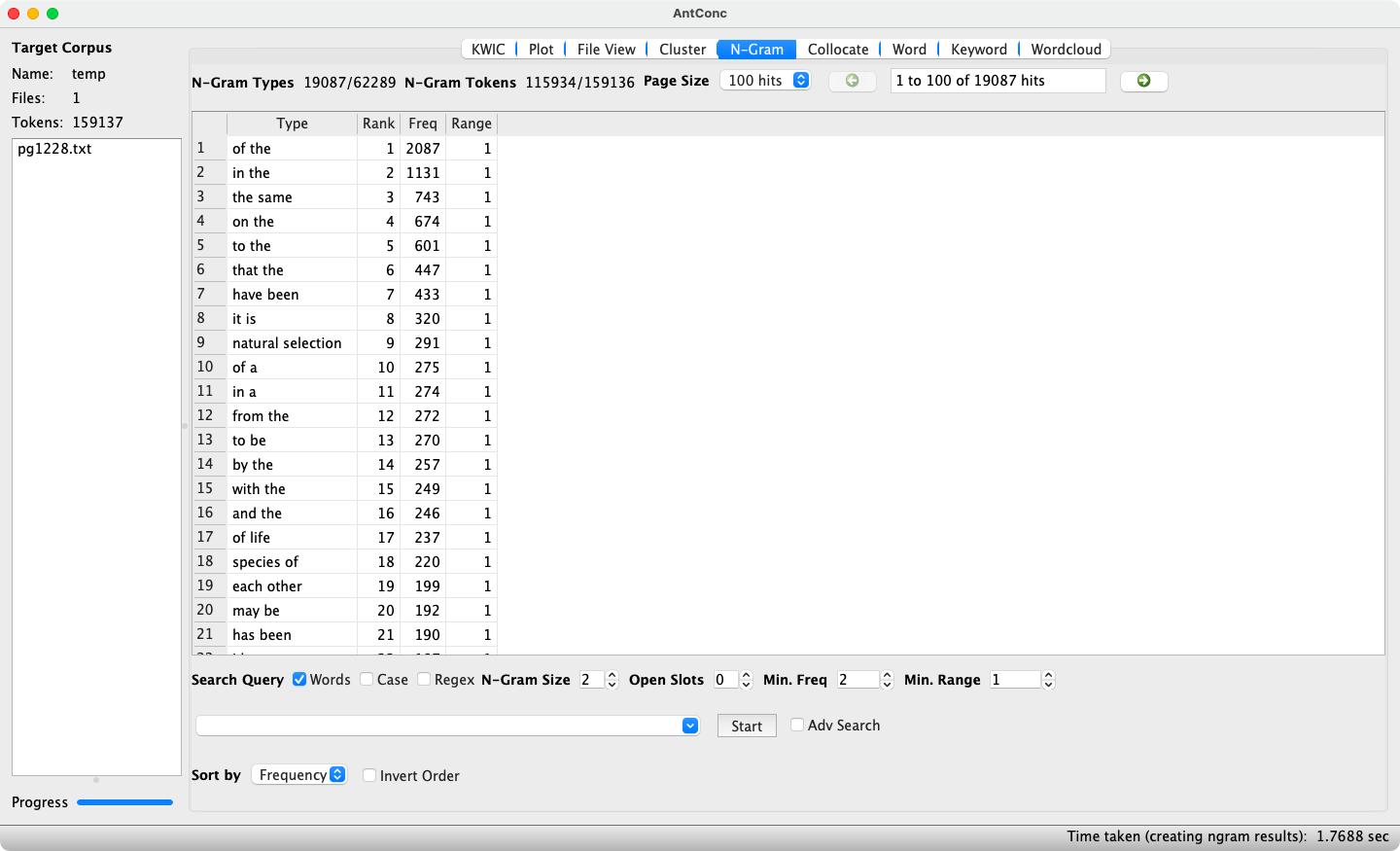
The N-Gram function is very similar to clustering, with the difference that rather than looking for clusters involving a specific search term, any clusters involving n words (with n being a natural number) in the text or corpus are identified. Setting a small n, as in 2-grams, typically reveals frequent combinations of function words such as prepositions, determiners, and auxiliary verbs (see Figure 8), whereas setting a higher n, as in 5-grams or higher, helps in identifying rigid constructions such as idioms and proverbs.
2.4 Word List
As its name suggests, AntConc’s Word List tool, which is accessible via the Word button, generates a list of words in a text or corpus. By default, words are sorted by their frequency, as shown in Figure 9.
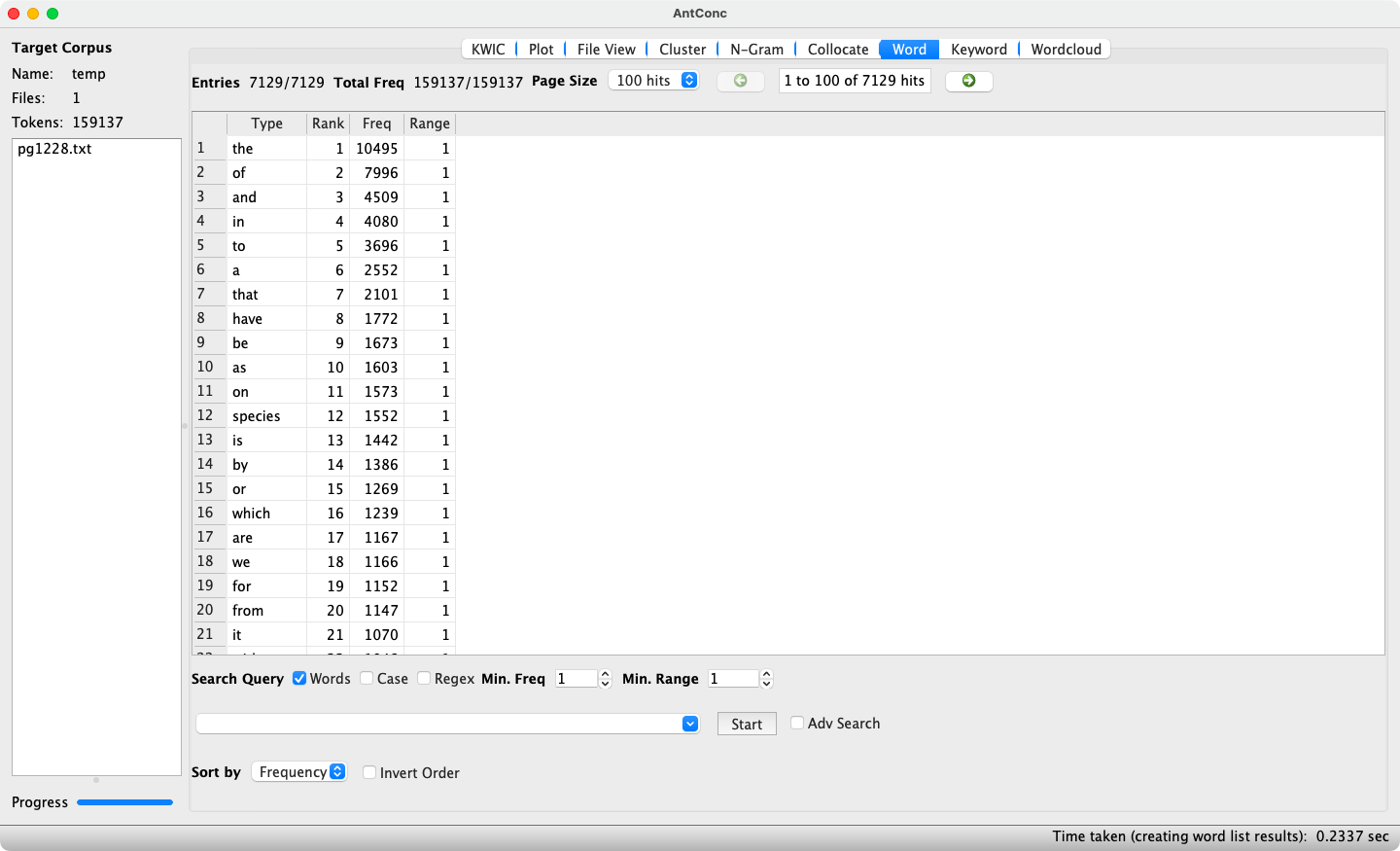
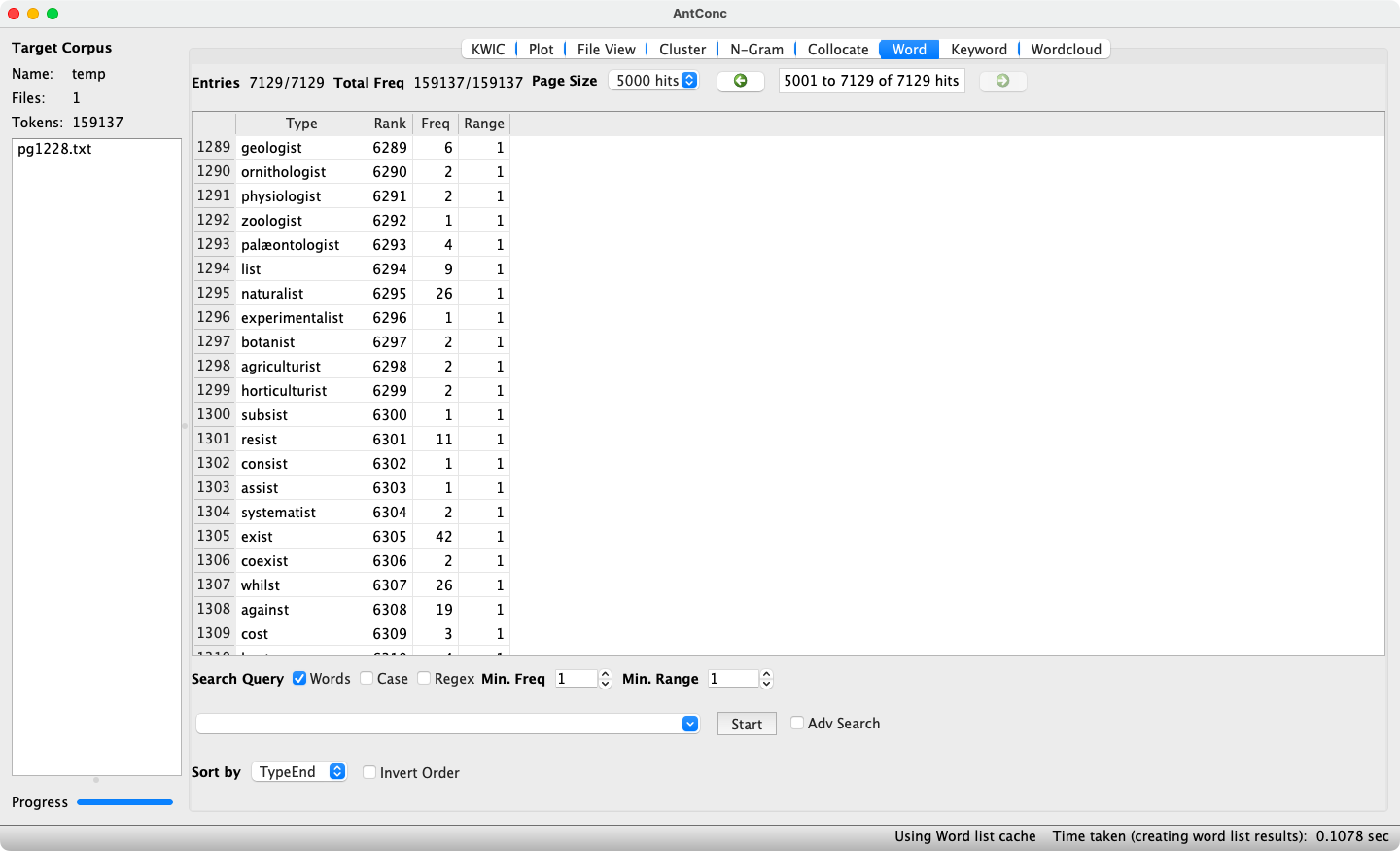
Further sorting options are Type, i.e. by alphabetical ordering of the words, and TypeEnd, i.e. sorting words alphabetically starting from their final character. While the latter option may seem odd at first glance, it is useful for identifying words formed with a particular suffix (as shown for {-ist} in Figure 10). The checkbox Invert Order is useful when wishing to inspect a prefix or suffix beginning/ending with a letter near the end of the alphabet, as it sorts the results from Z–A and thus reduces the amount of scrolling necessary.
2.5 Further reading
AntConc’s website contains a wealth of material, including help files, guides, discussion groups, and video tutorials.
3 CorpusSearch
CorpusSearch (Randall, 2010) is a tool to perform queries in corpora annotated in the Penn-Treebank format.
3.1 Installation
Detailed installation instructions are provided on the CorpusSearch website. Alternatively, students and staff of Anglistik Ⅳ at Mannheim University can use CorpusSearch via the search platform for Penn-Helsinki corpora.
3.2 Basics of CorpusSearch
CorpusSearch performs queries in corpora annotated in the Penn-Treebank format by using a query file (with the .q file ending) in which the query is formulated. Sentences from the corpus that match the query are copied into an output file (with the .out file ending).
The Penn-Treebank format uses sets of parentheses to represent the clause hierarchy, as illustrated in the example below (adapted from the CorpusSearch website).
( (IP-MAT (ADVP-TMP (ADV Then))
(NP-SBJ (D the)
(N child))
(VBD became)
(ADJP (ADJR happier)
(CONJ and)
(ADJR happier))
(E_S .)) )At the lowest level of the clause hierarchy, each word form is assigned a part-of-speech (POS) tag, e.g. N (noun), ADJR (adjective comparative), ADV (adverb), or VBD (verb past tense). At higher levels, elements carry syntactic information, e.g. NP-SBJ (noun phrase subject), ADVP-TMP (temporal adverb phrase), or IP-MAT (inflectional phrase, matrix clause). Thus, the format enables searches for specific words, but also word classes or syntactic structures. The query syntax used to perform such queries is outlined below.
3.3 CorpusSearch query syntax
3.3.1 Search Functions
The query syntax of CorpusSearch uses Search Functions, i.e. specific key words that describe specific relations between multiple arguments. For example, the search function Dominates indicates that the argument preceding the search function is at a higher level than the argument following the search function.
The queries (IP-MAT Dominates NP-SBJ) and (IP-MAT Dominates N) would return the example sentence displayed above as a match, whereas (IP-MAT Dominates PRO) would not, given that there are no pronouns in the sentence. The more specific search function iDominates (“immediately dominates”) yields different results, so that only the query (IP-MAT iDominates NP-SBJ) matches the example sentence. (IP-MAT iDominates N) does not result in a match as IP-MAT dominates N, but only indirectly, given the intermediate level NP-SBJ. An overview of some search functions is shown in Table 5.
| Search function (incl. variants) | Meaning | Example queries generating matches in example sentence |
|---|---|---|
Dominates, dominates, Doms, doms |
dominates to any generation | (N Dominates child), (NP-SBJ dominates N), (NP-SBJ Doms child), (IP-MAT doms child) |
iDominates, idominates, iDoms, idoms |
immediately dominates | (N iDominates child), (D iDoms the), (NP-SBJ iDoms N), (ADVP-TMP idoms ADV), (ADJP idoms CONJ) |
Precedes, precedes, Pres, pres |
precedes | (D Precedes N), (ADJ precedes ADJ), (NP-SBJ Pres VBD), (NP-SBJ pres ADJP), (the Precedes child) |
iPrecedes, iprecedes, iPres, ipres |
immediately precedes | (D iPrecedes N), (the iprecedes child), (NP-SBJ iPres VBD), (VBD ipres ADJP), (VBD iPrecedes ADJR) |
HasSister, hasSister, hassister |
is on the same hierarchic level | (D HasSister N), (ADJR hasSister CONJ), (VBD HasSister NP-SBJ) |
Exists, exists |
exists in the sentence | (ADJR Exists), (then exists), (NP-SBJ Exists) |
3.3.2 Unique referents
Once a tag or word has been used in a CorpusSearch query, any further mention will refer to the exact same instance. For example, queries such as (ADJR precedes ADJR), (ADJR hasSister ADJR), (happier precedes happier), or (happier hasSister happier) will not return matches for the example sentence shown earlier, even though the tag ADJR and the word happier occur twice at the same hierarchic level (lines 5 and 7). This is due to the fact that the tag ADJR and the word happier as used in the queries refer only to their first respective instances. As such, the queries make no sense, as a tag or word cannot precede itself, nor can it be its own sibling. In order to search for multiple instances of the same tag or word, each instance has to be disambiguated with a running number in square brackets. The previous queries should therefore be corrected: ([1]ADJR precedes [2]ADJR), ([1]ADJR hasSister [2]ADJR), ([1]happier precedes [2]happier), and ([1]happier hasSister [2]happier).
3.3.3 Wild cards
CorpusSearch supports two wild cards, namely * and #. The * character carries the same meaning as in regular expressions, that is “zero or more”. However, it is not only a quantifier, but functions as a combination of wild card and quantifier, meaning that it stands for any character sequence of any length. As such, it corresponds to the .* sequence in regular expressions. The * wild card is particularly useful when seeking portions of a tag. For example, any noun phrase can be referred to with NP-*, rather than having to specify all noun phrase tags individually, such as NP-SBJ (“noun phrase subject”), NP-OB1 (“noun phrase first object”), NP-OB2 (“noun phrase second object”), NP-SPR (“noun phrase secondary predicate”), NP-LFD (“noun phrase left dislocation”), etc.
The # wild card stands for digits, which is useful when searching for single words which are spelled as multiple words in the corpus. For example, the sentence below (taken from the PPCME2) can be matched with the query (PP iDominates P#).
( (IP-MAT
(ADVP-TMP (ADV Anone))
(PP
(ADVP (ADV there))
(P21 $with)
(P22 all))
(VBD arose)
(NP-SBJ (NPR sir) (NPR Gawtere)))
(ID CMMALORY,199.3136))The query finds the tags P21 (line 5) and P22 (line 6), which are both immediately dominated by PP (line 3). When combined, they correspond to the present-day preposition withal. The first digit signals how many parts the split word contains, whereas the second digit indicates the number of the current element.
3.3.4 Logical operators
CorpusSearch features the logical operators AND, OR, and NOT. The operators AND and OR can be used to string together multiple search functions within a query. For example, the sentence displayed above can be matched in a query that specifies that the matrix clause should contain a verb in the past tense and that the subject should feature a proper noun, expressed thus:
The use of the AND operator implies that the query will match sentence if, and only if, all search functions connected with AND return a match. If, for example, the verb were to be in the present tense, i.e. tagged as VBP, the sentence would not result in a match even though the subject contains a proper noun. Conversely, if the subject were to contain common nouns (tagged as N) rather than proper nouns, the sentence would not result in a match even though the verb is in the past tense.
The OR operator behaves differently. The following query would result in a match as long as at least one of the functions connected by OR finds a match:
The OR operator can also be used within the arguments of a search function with the | (pipe) character. For example, a query can be formulated that matches noun phrases that function as subjects or objects: (IP-MAT iDoms NP-SBJ|NP-OB*). This query will match the tags NP-SBJ, NP-OB1, and NP-OB2, but will exclude other NP-* tags such as NP-SPR or NP-LFD.
The NOT operator functions via the ! (exclamation mark) character. By placing it before an argument within a search function, it will exclude said argument. For example, the following query includes any tag immediately dominated by a noun phrase subject, with the exception of proper nouns: (NP-SBJ iDominates !NPR).
3.4 Further reading
The CorpusSearch website offers a detailed user manual. For each corpus annotated in the Penn-Treebank format, the respective annotation manual should also be consulted.
For details on how to perform queries in the lemmatised version of the Penn-Helsinki Parsed Corpus of Middle English (PPCME2, Kroch & Taylor, 2000), see the description of the PPCME2 in this site’s Corpora section and/or Percillier (2016, 2018).