This page introduces some basic concepts for the quantitative analysis of corpora, and also offers an introductory tutorial into R, a programming language for statistical analysis and graphics.
Table of contents
1 Basics and examples
Written by Tabea Harris
1.1 Types/tokens
In corpus linguistics we differentiate types from tokens. The term type refers to the number of word forms that are unique, whereas token refers to the total number of words (in a corpus or a sample). For instance, in COCA the word soliloquy occurs 283 times in total, i.e. for one type there are 283 tokens. It is a matter of particular research interests whether we would consider the word form sings as a type of its own or only the lemma sing. Consider the example sentence below. How many types and tokens can you identify?
The red lantern and the white lantern illuminated the room and gave it a reddish tinge.
When working with historical corpora, be aware of spelling variations. The English language was not fully standardized until the Early Modern English period. So if you encounter the noun colour in Middle English, you may notice a number of different forms such as coleour, cullour, or colowr, among many others. These would not count as different types, but are variations of one type.
One basic method of corpus statistics is the calculation of the type/token ratio, i.e. the relation between the number of types and the number of tokens. The type/token ratio can give some indication of how varied the vocabulary of a corpus is. It is calculated by dividing the number of types by the number of tokens in a corpus. When multiplied by 100, the type/token ratio can be expressed as a percentage. Let us take example 1 above to illustrate. We have 12 different types and 16 tokens in total. By using the calculation above we obtain a type/token ratio of 0.75 or 75%. The higher the ratio, the more nuanced the vocabulary is because it signals a high amount of types in relation to the overall tokens. However, the basic method can fail when the corpus is too large as words with a very high frequency (for instance, the article the) will likely skew the results. To circumvent this problem, a standardized type/token ratio is used by which the corpus is divided into equally-sized parts each for which a type/token ratio is calculated. The standardized type/token ratio then is the average of these individual ratios.
In this context, it is useful to have some information about words (or word forms) that only occur once in a corpus. These are called hapax legomena (hapax legomenon, sg.), which is of Greek origin and means ‘said only once’. Hapaxes can give some indication about new words (i.e. neologisms) but should not be confused with them. In doing so, they can be used to inform about the productivity of a word form. A linguistic item is productive when many new words can be formed with it. For instance, the derivational suffix -ness is considered quite productive because many new words are formed with it, whereas the suffix -th cannot be considered productive anymore. Aside from the existing derivations width, depth, breadth, and a few others, no new words are formed with -th. Productivity in affixes can be measured by taking the number of hapaxes with a particular affix and dividing them by the number of all tokens with that affix. For the sake of illustration let us consider an example from Plag, Dalton-Puffer, & Baayen (1999). They distinguished between two variants of the suffix -ful:
the so-called ‘measure -ful’ (e.g. handful) and
a ‘property -ful’ suffix (e.g. careful).
The overall tokens for (2) are 2,615 with the number of hapaxes amounting to 60. For (3), the number of tokens is 77,316 and the number of hapaxes is 22. If we use the calculation from above we obtain a productivity P of 0.023 for (2), and 0.00028 for (3). Which of the two is more productive given these numbers? Again, corpus size is crucial in determining ‘real’ hapax legomena. If a corpus is too small, the results may be skewed in that well-known and otherwise frequently used words only occur once.
1.2 Collocations
Introduced by Firth (1957), a collocation describes “actual words in habitual company” (1957, p. 14). In other words, collocations are words which characteristically occur next to particular other words with a high frequency. For instance, the adjective blue and the noun sky occur in sequence very frequently - they are collocates. A similar co-occurrence of the adjective turquoise and sky would be much less common and accepted. That adjective may be a collocate of another word, however (the noun water for example). Of course, collocations do not have to be directly adjacent to each other, but may occur in close vicinity to each other. In corpora, you are able to set the span of words within which a collocate of a given word may occur. Collocations can become more fixed by repeated use (i.e. they become lexicalised) and usually have a strong semantic connection. A special type of collocation is the so-called colligation which is situated at the grammatical level. A colligation involves the relationships of particular word classes to each other, for instance, a noun may tend to colligate with an adjective, rather than with another part of speech.
1.3 Co-occurrences
Co-occurrences are very similar to collocations in principle. The term describes linguistic units which co-occur with high frequencies that exceed mere chance within a sentence or an entire text. For example, you will probably find a high number of words like coffee and espresso bean co-occurring together in a text about coffee shops, but not so much in an article about language acquisition. It is assumed that these terms are interdependent if they co-occur in a text with an above-chance frequency. In corpora, very often you will only find the option of searching for collocations.
This section describes some ways in which statistics can be used with language data. Statistical analysis includes descriptive methods, i.e. counting and comparing what we can observe. Beyond that, we can use inferential methods, i.e. testing hypotheses and obtaining answers to research questions. Performing statistics requires mathematics — luckily, we can rely on computers to do the heavy lifting in that area. For this, we will use a piece of software called R(R Core Team, 2018), which is a free programming language for statistics and graphics, and is an emerging standard for statistical analysis in the field of linguistics.
This guide is designed as a hands-on tutorial, meaning that you will get the most out of it if you install R and the data sets, and perform each step of the analysis yourself (rather than just reading through the text). The section begins with an introduction on how to use R, before we can move on to data analysis using two dummy data sets, covering many of the statistical tests you are likely to find useful for your studies.
2.1 Getting started with R: basic concepts and functions
2.1.1 Installation
R is available for Windows, macOS, and Linux, and can be downloaded for free from the R website. While optional, I also highly recommend the installation of RStudio, an integrated development environment (IDE) for R. This tutorial assumes that both R and RStudio are installed.
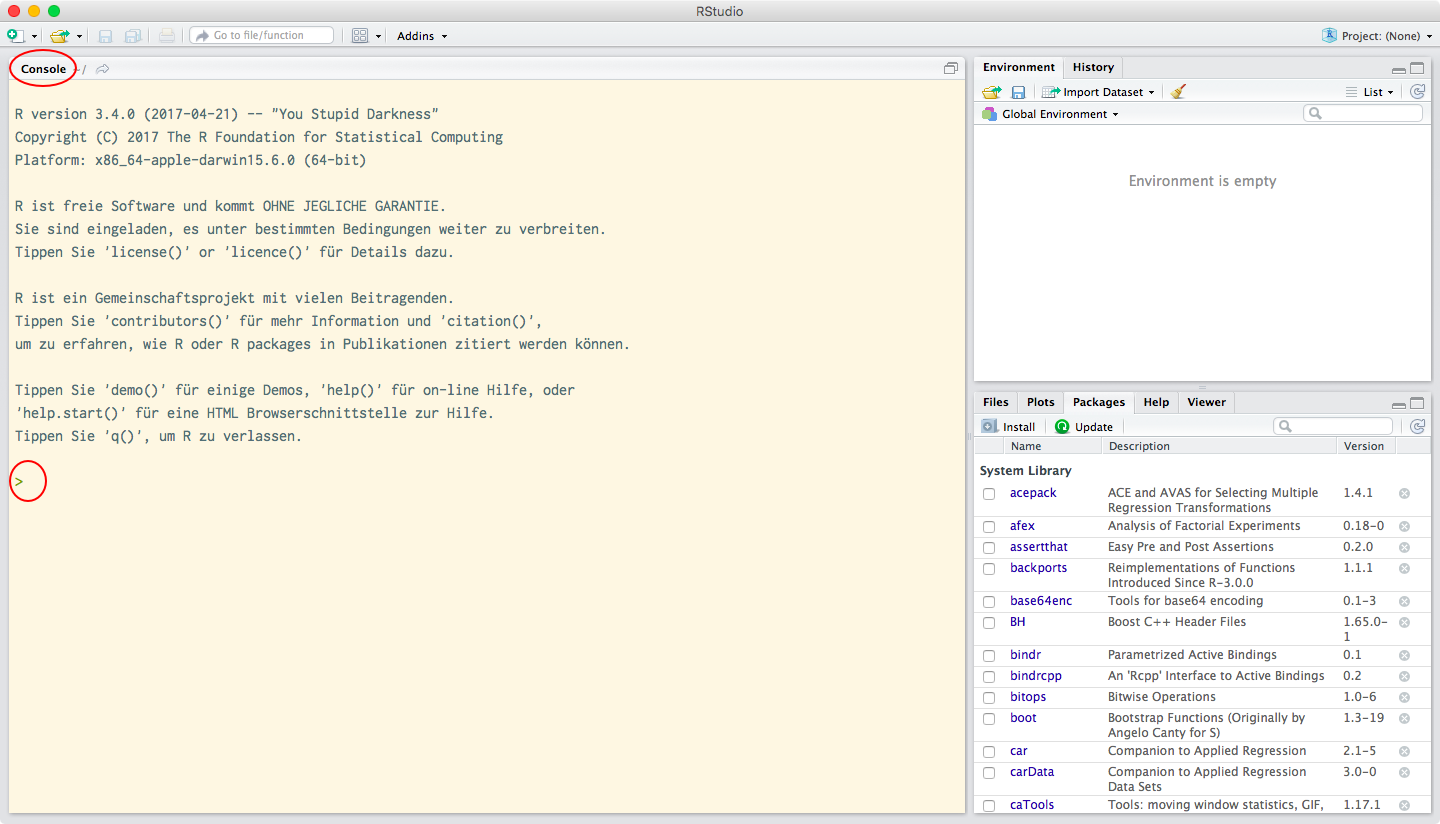
R functions via a Command Line Interface (abbreviated as CLI). This means that when first starting R, you are not faced with a graphical user interface with buttons to click, but rather with an empty text field, called a Console, in which commands can be entered. The position at which new commands can be entered in the console is called the Prompt, and is signalled by the > (greater-than sign) character (see Figure 1).
Figure 1. Position of the console and the prompt in RStudio
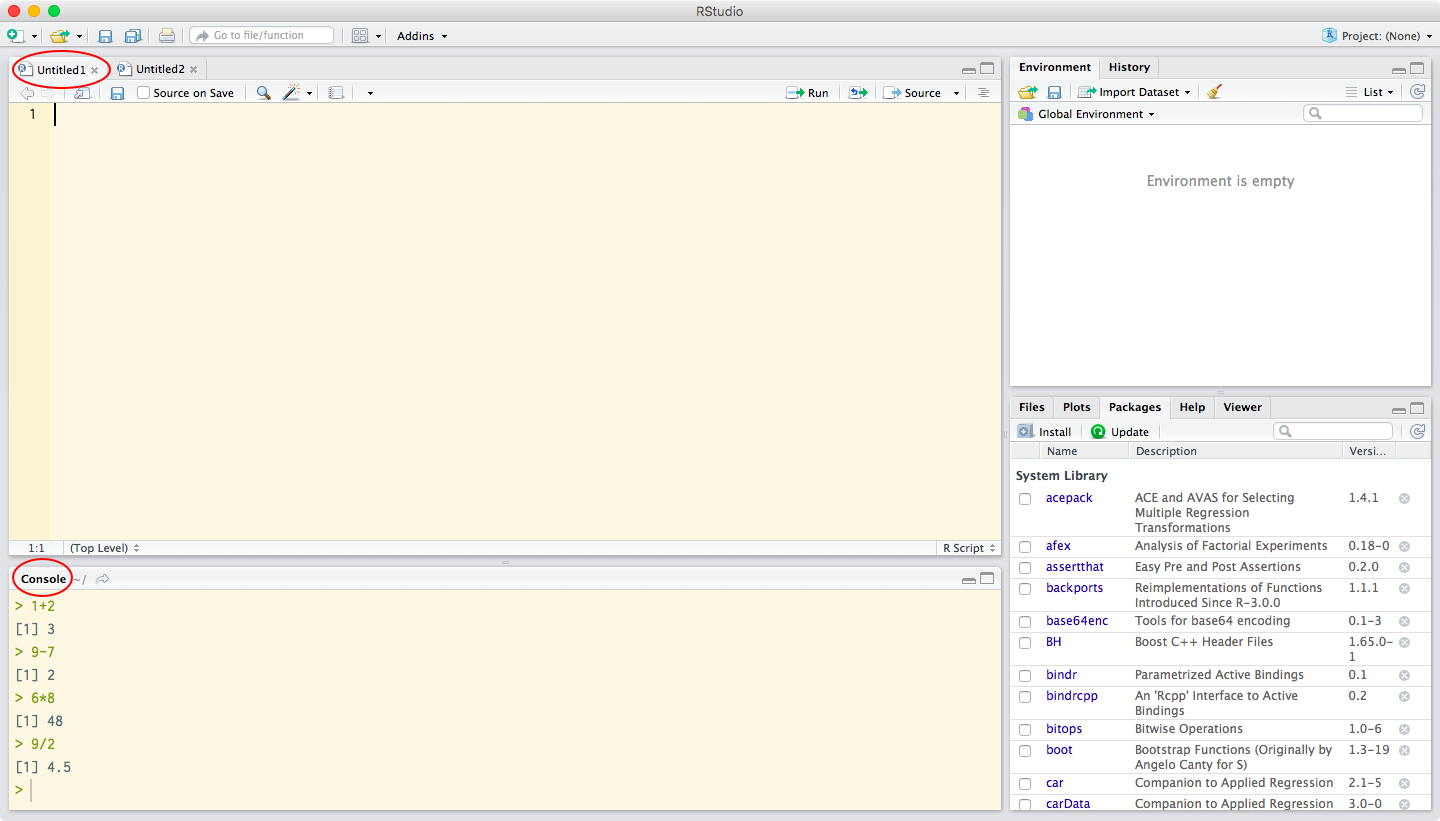
Commands are entered at the prompt and executed by pressing the (Enter) key. Once a command is executed, its results are displayed in a new line, after which a new prompt appears, ready to receive a new command. The entering and execution of commands in the console is shown in Figure 2.
Figure 2. Demonstration of simple mathematic operations in the console of RStudio
The console keeps a history of executed commands, which can be navigated with the ↑ (up arrow) and ↓ (down arrow) keys at the prompt. This prevents any retyping or copy-pasting of previous commands.
Rather than entering and executing individual commands in the console, these can be entered and saved in a script editor window. The advantages of using the script editor are the ability to execute multiple commands at once, as well as the ability to store the commands in a text file with the file ending .R for later use and documentation of one’s methodology.
A new script editor window is created via the File > New File > R Script menu (shortcut ++N on Windows/Linux, +⌘+N on macOS). The creation of a script editor window reduces the size of the console, and multiple script editor windows can be opened and accessed via tabs, as shown in Figure 3.
Figure 3. Position of script window(s) (top) and the reduced console (bottom) in RStudio
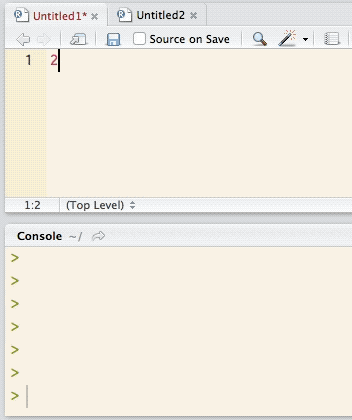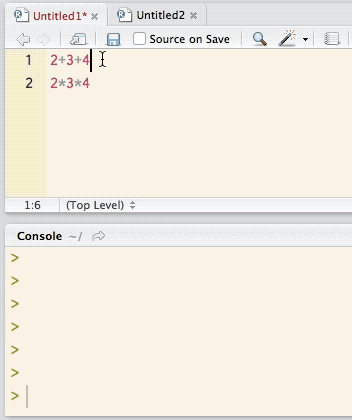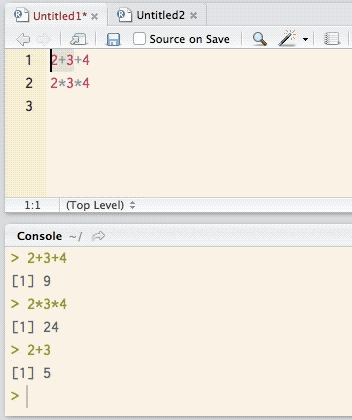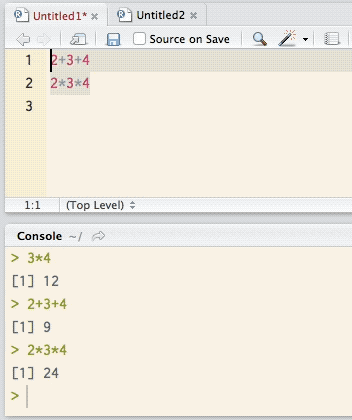
When typing commands in the script editor, note that pressing the (Enter) key does not execute the command, but rather jumps to a new line, much like in a text editor (which the script editor basically is). Commands can be executed directly from the script editor with the key combination +R (Windows), + (Linux), ⌘+ (macOS). The effect of this key combination varies depending on the position of the cursor or the amount of selected text, as demonstrated in Figure 4.
Figure 4. Interaction between the script editor and the console in RStudio
As can be seen in Figure 4, placing the cursor anywhere on a line before using the key combination copies the entire line to the console and executes it. However, when only parts of a line are selected, as shown for 2+3 in line 1 and 3*4 in line 2, only the selected portion is copied to the console and executed. In the same vein, multiple lines can be selected and executed at once from the script editor.
Saving a script is achieved via the File > Save menu (shortcut +S on Windows/Linux, ⌘+S on macOS). Opening a previously generated R script file is achieved via the File > Open File... menu (shortcut +O on Windows/Linux, ⌘+O on macOS).
Variables are names under which values are stored and accessed. This storing process uses the character sequences <- (less-than + hyphen/minus) or -> (hyphen/minus + greater-than), which represent an arrow pointing to the left or right respectively. This arrow points towards the variable name, so that the variable name can occur before its assigned value using the left-pointing arrow, as in variable <-value, or after its assigned value using the right-pointed arrow, as in value ->variable. Once defined, the variable behaves just like its value.1
It should be noted that unlike in mathematics, variable names can be chosen freely. Given this freedom, I recommend using expressive variable names, i.e. names that provide information regarding the content or the purpose of the variable. Variable names cannot contain spaces. Common workarounds are the capitalization of the first letter of each new word (so-called camelCase), as in aVariableName, or the use of dots between words, as in a.variable.name. Some examples of variable usage are shown in the example below.
Notice how the definition of variables in lines 1 and 2 does not produce any output. This is because the command was simply to assign a variable name to a value. To see the content of a variable, enter its name as a command. This will show its contents as output, as seen in lines 3-4 and 5-6. Once defined, using a variable name in commands produces the same results as using its value, as shown in lines 7-12. Variables can be used to define further variables, as shown in lines 13-15.
The values that variables can adopt are not limited to numbers, but include a variety of Data Types, for example text strings. Text strings need to be enclosed in quotation marks, either double " " or single ' '. Double quotation marks are required if the text string contains apostrophes.
Functions are pre-defined sets of operations applied to data. The format of functions consists of a function name directly followed by parentheses in which the data and optional parameters can be specified. Such data objects and parameters indicated in parentheses are called Arguments of a function, and are separated by , (comma). A few examples of functions are given below.
The # character (octothorpe/hash sign/pound sign) indicates a Comment. Any character occurring after # in a line will be ignored by R, and can thus be used to describe the code. This can be done by commenting on code within the same line, as done in line 21, or by dedicating entire lines to comments, as done in lines 23-24 and 27. Comments are crucial as they allow documentation of the code, such as what the code achieves and why.
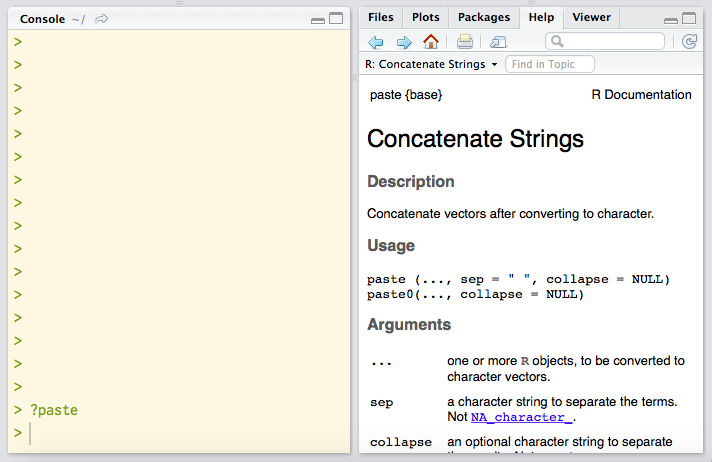
Line 28 specifies a separator parameter for the paste() function. This presupposes that one should know what arguments the function has, and what its default values are. This information can be looked up in the R documentation. The documentation for a given function can be accessed by entering a function name preceded by a ? (question mark) in the console. Figure 5 shows how entering the command ?paste in the console causes the documentation for the paste() function to appear in the Help panel.
Figure 5. Example of an R Documentation entry displayed in the Help panel of RStudio
The documentation entry shown in Figure 5 shows that the function paste() has a parameter called sep with the default value " " (space character). Please note that the parameter is a text string that has to be specified in quotation marks. If a function’s parameter is not specified in a function call, the parameter will be used with its default value, as shown in lines 25-26. To override the default value, the parameter and its desired value must be specified in the function call, as shown in lines 28-29.
In lines 34-35 and lines 40-41, the contents of two vectors are displayed, each containing 20 values. When the contents do not fit into the width of the console, the display continues on an additional line. Each display line begins with the Index Number of the first displayed item enclosed in [ ] (square brackets). For example, line 34 begins with the first item of the vector myFirstVector, and line 35 continues with its thirteenth item. To access a specific item in a vector, use its index number in square brackets, e.g. myFirstVector[9] to access the ninth item. Please note that unlike in most other programming languages, index numbering begins at 1 and not at 0.
Line 43 showcases the c() function, which combines multiple arguments into a new vector. In this specific instance, the 20 items of myFirstVector are combined with the 20 items of mySecondVector, which now form items 21-40 of the new vector. The arguments used with c() do not have to be vectors themselves. Combining individual numbers, such as c(1,3,5), will create a new vector [1,3,5]. It should be noted that all items in a vector have to belong to the same data type. When combining numbers and character strings, numbers will be converted to character strings. For example, the command c(10,"green","bottles") will create the vector ["10","green","bottles"], where the quotation marks around 10 indicate that the item is a character string and not a number.
Numerical vectors can be used with mathematical Operators, as shown in line 49. Rather than combining the values as done with c(), using the + operator on two numerical vectors results in a new vector that has the same length as the input vectors. For each index position, from 1 to 20 in this particular example, the value from myFirstVector is added to the value of mySecondVector at the same index position. You can try this with other mathematical operators such as - (subtraction), * (multiplication), and / (division).
A vector with two dimensions is called a Matrix, and behaves like a table with rows (dimension 1) and columns (dimension 2). The creation of a two-dimensional matrix from two one-dimensional vectors is shown in the example below.
The functions rbind() and cbind() combine vectors into matrices by rows and columns respectively. Notice how the matrix generated with the rbind() function contains two rows, corresponding to the two input vectors, and twenty columns, corresponding to the length of the input vectors. The display of twenty columns does not fit into the console, so the columns are displayed in separate chunks according to the console width.
As matrices are two-dimensional, accessing their contents via index numbers require two indices. As with vectors, index numbers are specified in square brackets, with the difference that the dimensions are separated by a comma. Therefore, accessing the table cell in the position “row 1, column 2” should be specified with myFirstMatrix[1,2]. To access entire rows or columns, leave a dimension blank. The sequence myFirstMatrix[1,] therefore refers to “row 1, all columns”, i.e. the entire first row of myFirstMatrix, whereas myFirstMatrix[,2] refers to “all rows, column 2”, i.e. the entire second column of myFirstMatrix.
Data can be imported into R for analysis. The data format best suited for importation is CSV (short for Comma-Separated Values), which can be easily exported from spreadsheet applications such as Microsoft Excel, OpenOffice/LibreOffice Calc, or Apple Numbers and then imported into R. In this format, tables are represented as plain text, with each text row corresponding to a table row, and columns separated by commas or similar characters, such as semicolons or tabs. The structure of a CSV table is shown in an example below.
Two main conventions exist for CSV files: 1. The use of , (comma) as a column separator and . (period/full stop) as a decimal separator (so that 1.5 means “one and a half”), mainly used in English-speaking countries; 2. The use of ; (semicolon) as a column separator and , (comma) as a decimal separator (so that 1,5 means “one and a half”), mainly used in continental Europe.
Proprietary spreadsheet applications such as Excel or Numbers tend to export CSV files with the settings corresponding to the operating system locale. For example, a computer with an operating system set to English will export CSV files with the , separator, whereas a computer with an operating system set to German will export CSV files with the ; separator. Open-source spreadsheet applications such as OpenOffice/LibreOffice Calc let the user choose which CSV format to use.
R provides a function to import CSV files, called read.csv(). Its default parameters correspond to the Anglophone CSV convention. To import CSV files set in the European convention, the function read.csv2() can be used. Any other CSV format should be matched by manually adjusting the parameters of the read.csv() function. The list of available parameters is listed in the documentation of read.csv(), which is accessed via the ?read.csv command.
The present tutorial will use two data sets, esvio.csv and reading.csv.2 You will need to download the data sets from the links below to follow the rest of the tutorial.
Let us begin by importing esvio.csv into R. Opening the CSV file in a text editor should reveal the file’s CSV format, and therefore whether read.csv() or read.csv2() should be used. In both cases, the column separator is ;, and read.csv2() should be used. By default, both read.csv() and read.csv2() assume that the first row is a header row. You should therefore check whether the first in a CSV file is a header row, or the first data row. In the CSV example shown above (taken from esvio.csv), the first line is the header row, meaning that it specifies the column names. If there is no header row, the parameter header should be set to header=FALSE so that the first line should be treated as a table row rather than a list of column names.
There are three ways to specify the location of the file to be imported. The simplest method is to use the file.choose() function, which opens a system dialogue asking the user to select the file. The other methods involve specifying a path to the file. This can be done by giving the entire file path, or by first setting the working directory and then giving a relative path to the file. The three methods are shown in the example below.
The advantage of setting the working directory is that multiple files can be imported from the directory without having to specify the full file path each time. The current working directory can be checked using the getwd() function. If the path methods seem daunting, you may of course stick to the file.choose() method.
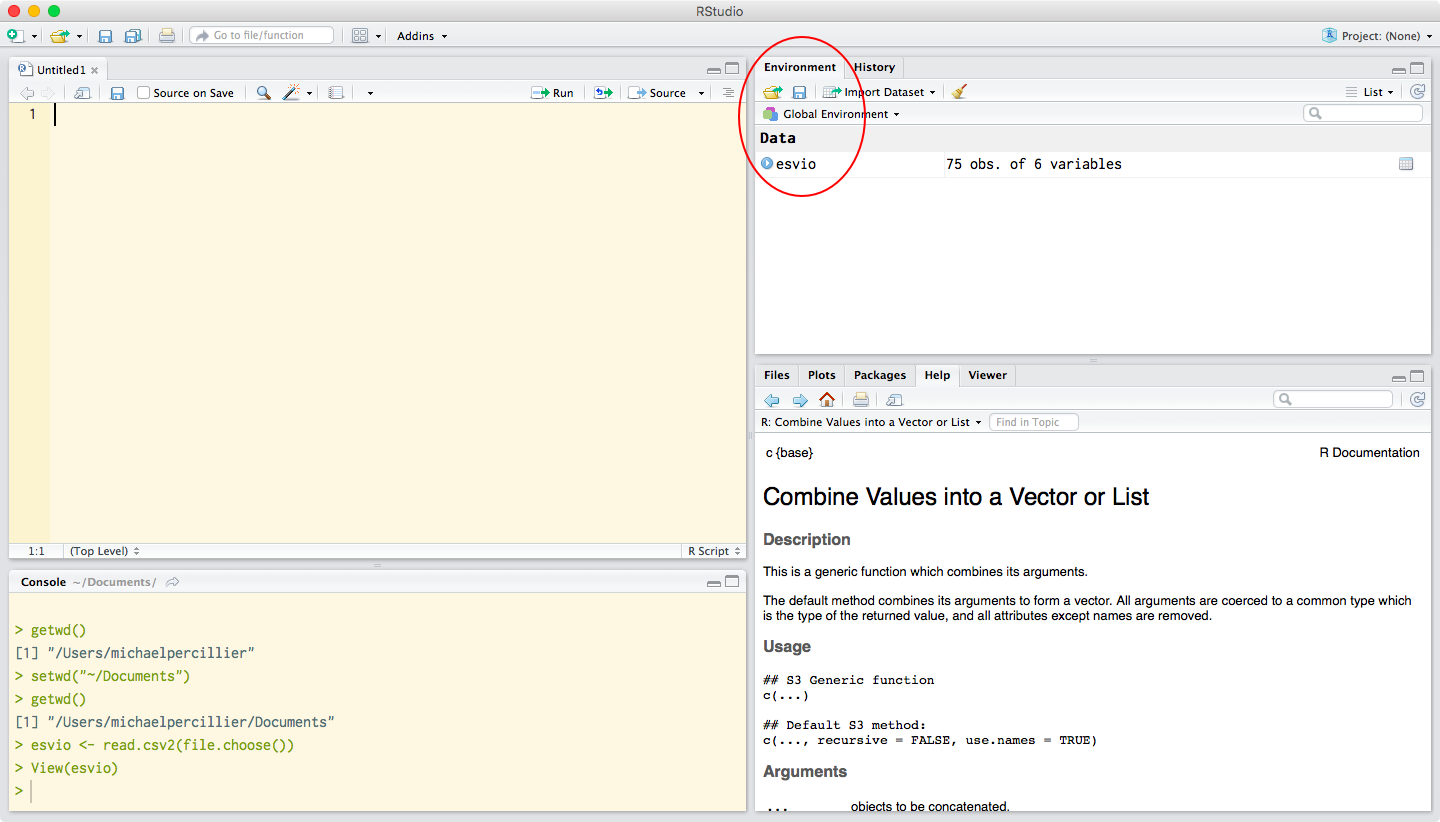
What all methods have in common is that the import is saved as a variable called esvio. If the read.csv() or read.csv2() functions are executed without being assigned to a variable, the content of the CSV file will be shown in the console, but the table will not be stored. Saving the table under a variable name ensures that the data is stored and can be used within R. Under RStudio, saved variables are listed in the Environment tab (see Figure 6).
Figure 6. Example of a saved variable listed in the Environment tab in RStudio
To verify whether the data was successfully imported, it is often useful to inspect the first and last rows. This can be done with the head() and tail() functions, as shown in the example below.
The default parameter of six rows for the functions head() and tail() can be adjusted manually, e.g. head(esvio,n=5) or tail(esvio,n=10). The entire table can also be viewed in a separate window with the View() function, e.g. View(esvio). Clicking the little table icon of a variable listed in the Environment tab will have the same effect as calling the View() function. If the table is not formatted as expected, e.g. because it has an empty row at the bottom, it may be necessary to fix the CSV file and reimport it.
Data imported from a CSV file is in a format called a Data Frame, which is a special type of matrix. The advantage of data frames is that columns can be accessed by their name using the $ (dollar) character. For example, the call esvio$word_order refers to the data frame’s first column, and is therefore equivalent to esvio[,1].
A very useful function for inspecting data frames is the summary() function. As its name implies, it provides a summary of an object, as shown in the example below.
A summary of a data frame provides details for each individual column. Summaries can also be obtained for specific columns, which may be necessary for columns with too many Levels. In the example above, the column $speaker_ID contains too many levels (which correspond to individual speakers) to be displayed in the global summary of the data frame. Levels are displayed by decreasing frequency, and after the sixth level, remaining data are grouped as “Other”. To obtain a complete summary of the $speaker_ID column, the summary() function can be applied to this specific column, which returns an entire summary, this time sorted alphabetically rather than by frequency.
In a data frame such as esvio, rows correspond to Tokens, i.e. individual Observations, and columns correspond to Variables. To avoid confusion with the concept of variables in the programming sense introduced earlier, the more specific term Statistical Variable will be used consistently.
The summaries of statistical variables shown in lines 118-125 above reveal that $speaker_age behaves differently from the other statistical variables. While $speaker_age consists of numbers and is therefore a Numeric statistical variable, the other statistical variables contain categories called levels. Such categorical statistical variables form a data type called a Factor. This difference explains the two types of summaries encountered: 1. mathematical properties on the one hand, such as minimum and maximum values, mean and median, etc. for numeric statistical variables; 2. a list of levels/categories with frequency information for categorical statistical variables.
If in doubt, the status of any object can be tested with functions such as is.numeric(), is.factor(), or is.data.frame(). The function str() (short for structure) also reveals the object type alongside further information. The usage of these functions is shown below.
The goal of a statistical test is to probe whether one or more Independent Variables exert an influence over a Dependent Variable. For example, it is conceivable that originating from a given geographical region (North, South etc.), having a certain gender (female or male), or belonging to a certain age group (child or adult) can influence our language production. However, speaking a certain way cannot turn us into Northerners, women, or children. For this reason, statistical variables corresponding to linguistic phenomena will most often be the dependent variable, with non-linguistic statistical variables acting as independent variables that may influence language production.
The influence of an independent variable on a dependent variable is demonstrated by refuting a Null Hypothesis (abbreviated H0), which states that any observed patterns are strictly due to chance. By showing that chance cannot be the explanation, the influence of the independent variable become the “next best” explanation.
The probability of H0 being true is measured with a probability measure p, which ranges from 0 (absolutely impossible) to 1 (inevitably true). The closer p is to 0, the less likely the observed patterns are due to chance, and the more likely it is that the influence of the independent variable is responsible for any observed effects. Table 1 below shows the Levels of Significance, also called Alpha Levels, that are commonly used in linguistics.
Table 1. Overview of significance levels
p value
Level of significance
Abbreviation
p ≥ 0.05
Not significant
n.s.
0.05 > p ≥ 0.01
Significant
*
0.01 > p ≥ 0.001
Highly significant
**
p < 0.001
Extremely significant
***
Depending on the types of statistical variables to be tested, different statistical tests should be used to estimate p, as shown in Table 2.
Table 2. Overview of statistical tests by variable type to be compared
Categorical variable
Numerical variable
Categorical variable
χ2 test, Fisher test
-
Numerical variable
t-test, Wilcoxon test
Correlation test
The use of the different tests listed in Table 2 is described in detail below.
Let us test whether the independent variable $dialect_area influences the dependent variable $word_order in our data frame esvio. The corresponding research question is thus:
Does a speaker’s geographical location influence their word order?
For the purpose of statistical testing, the following H0 can be formulated:
Geographical location has no influence on word order, and any observed variations between regions are due to chance.
In order to test this H0, we count how often speakers from each region produce which word order. In R, we achieve this by using the xtabs() function (short for cross-tabulates). The function requires a formula beginning with a ~ (tilde) followed by the column names to be cross-tabulated, each separated by a + (plus sign). The name of the data frame in which the columns are stored is specified afterwards following a comma. Saving the output of the xtabs() function under an expressive variable name makes the table readily accessible for further analysis.
A first glance at the table orderXarea reveals that SVO is more frequently used in the North and Northeast whereas VSO is more frequent in the East. Given that the number of tokens differ for each region, a version of the table in percentages should offer a better view of the proportions of SVO and VSO in each region. The function prop.table() turns all values of the table into proportional ones so that the sum of the entire table is 1. This default behaviour can be altered with the parameters 1 for a sum of 1 per row, or 2 for a sum of 1 per column. As we want the proportions of SVO and VSO per region, the parameter 2 is the appropriate one. Further, we multiply the table by 100 as we want values in per cent rather than in “per one”.
The tables orderXarea and orderXarea.perc can also be represented as visual plots. The function barplot() generates such plots. Besides the name of the table to be plotted, the function accepts parameters such as xlab for a descriptive label on the x-axis, ylab for a similar label on the y-axis, and legend, which can be set to TRUE (or simply T) for an automatically generated legend in the top-right corner of the plot. The plots generated by the commands in lines 165-166 are shown in Figure 7.
Figure 7. Bar plots of orderXarea (left) and orderXarea.perc (right)
One of the statistical tests that can be used in this situation is the χ2 test (pronounced chi square /kʌɪskwɛː(r)/, with χ/chi being the 22nd letter of the Greek alphabet). The test functions by comparing the table of observed values with a table of Expected Values, i.e. values that one would expect if p = 1. These expected values are obtained by applying Equation (1) to each cell of the table.
This yields a parallel table in which each row and each column display equal proportions, which corresponds to a complete lack of influence of one statistical variable upon the other. The test compares the tables of observed and expected frequencies by subtracting the expected value from the observed value for each cell. The resulting value is squared so as to avoid that positive and negative differences neutralize each other. These squared differences for each cell are then added, yielding a χ2 value. The larger this value, i.e. the greater the differences between the observed and expected frequencies, the harder it is to support H0. The formula to estimate χ2 is given in Equation (2).
The function chisq.test() takes care of all the necessary computations and only needs the name of the table with the observed values to perform the test and return a p value.
The test returns three values: the χ2 value, the df (degrees of freedom), estimated as shown in Equation (3), and the p value, which is calculated from χ2 and df, as larger tables may have greater χ2 values for H0 to become untenable.
df = (\textit{number of rows} - 1) \times (\textit{number of columns} -1)(3)
The test suggests that the influence of the independent variable $dialect_area on the dependent variable $word_order is highly significant. When reporting the results in a paper, all three values returned by R should be given, for example in the following format, common in linguistic publications:
χ2=13.631, df=2, p=0.001097**
A further format more commonly used in psycholinguistics, as described in the department’s ABCs of Style, also requires the sample size:
χ2(2, N = 75) = 13.631, p = .001097
The χ2 test actually provides further details, such as a measure called Pearson’s residuals, estimated for each cell as shown in Equation (4).
If you compare the formula for Pearson’s residuals, shown in Equation (4), to the formula for the χ2 test, shown in Equation (2), you may notice that the Pearson’s residuals are a sort of “unsquared χ value”. In other words, the difference between observed and expected values is measured in the same way, but the positive or negative value is maintained, so that one can see, for each table cell, whether the expected value is smaller or greater than the observed value. The chisq.test() function stores Pearson’s residuals under the name $residuals, and this table can be plotted (Figure 8) to see the deviations between observed and expected values. For such a bar plot, it is best to specify the parameter beside=TRUE, as bars with positive and negative values will not stack. The plot shown in Figure 8 suggests that the region “East” deviates most from the other regions by strongly favouring VSO over SVO, whereas the other regions show a preference for SVO.
Figure 8. Pearson’s residuals from a χ2 test on the influence of $dialect_area on $word_order
Let us test the influence of individual speakers over word order production. The corresponding research question could be:
Do speakers tend to vary freely between SVO and VSO, or do speakers tend to favour one pattern over another?
And the corresponding H0 would be:
Individual speakers do not favour one variant over another, but tend to use both patterns in equal measure.
To test this H0, we perform the same analysis as above by just substituting the independent variable $dialect_area with the independent variable $speaker_ID.
Performing the χ2 test returns a warning that the estimation of the χ2 value may be incorrect. This happens when at least one value in the table of expected frequencies is below 5. The table of expected values is stored by the chisq.test() function under the name $expected. Looking at the table reveals that indeed all values are under this threshold.
Such a warning should be heeded, especially when the p value is close to the level of significance, as is the case here. In such cases, an alternative test, called Fisher’s Exact Test, can be used.
Practice the use of the χ2 test by probing the influence of the independent variables $age_group and $gender on the dependent variable $word_order.
The chisq.test() function stores a table of expected values under the name $expected, so for example chisq.test(orderXarea)$expected. Create a proportional bar plot (as in the right plot of Figure 7) and compare it to the proportional plot based on observed values. How does this comparison help in understanding the differences between observed and expected values, and the principle behind the χ2 test?
The χ2 and Fisher tests described above are not suitable for all investigations of one statistical variable upon another, as not all variables represent categories. For example, the statistical variables $age_group and $speaker_age contain the same information, but organized differently: whereas $age_group distinguishes the groups “old” and “young”, $speaker_age contains the actual ages measured in years, and is therefore a numerical variable. The testing of a numerical and a categorical variable consists in splitting the numbers contained in the numerical variable into groups corresponding to the levels of the categorical variable and comparing the distribution of the numbers within each group.
A convenient method to perform such comparisons in R is to use the by() function,3 which takes at least three arguments: the numerical variable to be investigated, the categorical variable whose levels should be used to group the values of the first argument, and the function to be applied to each separate group. For example, the mean age of speakers producing each word order can be estimated thus:
This suggests that on average, speakers who produce VSO tend to be older. Other functions can be used with by() or tapply(), such as summary(), which returns additional numerical information compared to mean():
The preferred statistical test to probe the differences between numerical values divided into two groups is the t-test.4 The t-test is a so-called parametric test, meaning that the data need to fulfil certain conditions, or parameters, for the test to be reliable. In the case of the t-test, this parameter requires that the data in both groups follow a normal distribution, which, in a nutshell, means that the data points are symmetrically distributed around the mean.
There are multiple ways to determine whether a distribution is normal. One is via visual analysis of distribution curves. A convenient function to draw both distributions at once is the densityplot() function from the “lattice” package (Sarkar, 2008). In R, packages are collections of additional functions that need to be installed and loaded.5 The package “lattice” needs to be installed only once, but loaded during each R session in which its functions should be used. The installing and loading of “lattice” and the use of densityplot() is shown below.6
Figure 9. Density plot of speakers ages grouped by word order
The plot shown in Figure 9 suggests that the age distribution of speakers who produce VSO appears to be approximately normally distributed (although there are two peaks on either side of the mean rather than a single peak at the mean), whereas the age distribution of speakers who produce SVO has a “left peak”.
A further method to check whether data are normally distributed is the Shapiro-Wilk test. Its H0 is that the data are normally distributed, and this H0 can be supported if p ≥ 0.1. As shown below, running the test on both samples simultaneously reveals that the age distribution of speakers who use VSO is close enough to a normal distribution, whereas the same cannot be said for the age distribution of speakers who use SVO.7
Given that one of the samples does not follow a normal distribution, the t-test should not be used.8 Instead, a non-parametric test should be used as an alternative, for example the Wilcoxon Rank Sum test, also called the Mann-Whitney test. The test works by ranking the numerical data, i.e. by giving the oldest age the rank 1 and the lowest age the last rank of 75, and verifying how these ranks are distributed across the two groups SVO and VSO. The idea is that if the ranks alternate between both groups, e.g. ranks 1, 3, 5, 7, etc. in group SVO and ranks 2, 4, 6, 8, etc. in group VSO, the differences between both groups should not be significant. If however most of the high ranks occur in one group and most of the low ranks occur in the other, the H0 cannot be maintained.
The ranking procedure is demonstrated for a sample of six tokens for each group in Table 3. In case of ties, i.e. of an age value occurring more than once, the mean rank is estimated. For example, the oldest age, 69 years old, occurs six times, while the second oldest age, 61 years old, occurs four times. Thus, the value 69 occupies the ranks 1-6 and the value 61 occupies the ranks 7-10. The mean for the ranks 1-6 is computed as (1+2+3+4+5+6)/6, which yields the result 3.5. For the ranks 7-10, (7+8+9+10)/4 yields the value 8.5.
Table 3. Sample of six tokens per word order group, ranked by speaker age values
Token n°
word_order
speaker_age
rank
1
SVO
28
62.0
2
SVO
28
62.0
3
SVO
28
62.0
4
SVO
23
70.0
5
SVO
23
70.0
6
SVO
61
8.5
7
VSO
61
8.5
8
VSO
55
15.0
10
VSO
34
39.5
11
VSO
34
39.5
15
VSO
42
31.5
17
VSO
34
39.5
For each group, the rank values are added, as shown in Equations (5) and (6). Then, a W value can be computed using the rank sum for the first group and the number of observations in each group using the formula shown in Equation (7). The higher the W value, the more significant the differences between the two groups.
The differences between the two groups can therefore be said to be highly significant. A method to visualize the interaction between categorical and numerical statistical variables is the Box and Whiskers Plot (sometimes just called box plot). The boxplot() function, shown in the lines below, uses the same format as the t.test() and wilcox.test() functions.
Box plots consist of a box that represents 50% of the data surrounding the median value, itself represented by the thick black line in the box. Expressed differently, the lowest 25% of the data are underneath the box, the second-lowest 25% range from the lower edge of the box to the median line, the second-highest 25% range from the median line to the upper of the box, and the highest 25% are located above the box. The cut-off point delimiting the bottom 25% from the second lowest 25% is called the First Quartile, while the cut-off between the highest 25% and the second-highest 25% is called the Third Quartile. The data between these two points, which corresponds to 50% of the data surrounding the median, lie in the Interquartile Range. If you look closely at the box plot in Figure 10, you may notice that the bottom and top margins of the boxes correspond to the values previously displayed in lines 219-226. The whiskers capture any data points outside the interquartile range, i.e. outside the box, but may only extend 1.5 times the size of this range, i.e. they may only be 1.5 as large as the height of the box. Any points that cannot be captured by the whiskers are plotted individually and can be considered Outliers, i.e. instances that are extraordinarily small or large and do not reflect the overall trend in the data. The boxplot() function offers a notch parameter which draws notches in the side of each box. If these notches do not overlap, it is likely that the differences are significant.
Figure 10. Box and whiskers plot of age distribution by produced word order, displaying a notched version in the right pane
It is important to keep in mind that the p value returned by a statistical test merely indicates the extent to which the observed differences may be due to chance. For example, a p value of 0.05 still holds a 5% (or 1 in 20) risk of reporting a significant difference when there is none. Most tests are sensitive to sample size, meaning that with very large sample sizes (e.g. comparing the frequencies of all nouns and verbs across different genres in a multi-million word corpus), a test may return a significant p value no matter what. To remedy this problem, one can estimate the Effect Size, also called Measure of Association, i.e. the amount of impact an independent variable has on a dependent variable (Murphy & Myors, 1998, p. 12). It is recommended to report the effect size in addition to p values (Wilkinson & Task Force on Statistical Inference, 1999, p. 599).
For the χ2 test, the measure of effect is Cramér’s V, sometimes called Cramér’s φ (phi /faɪ/, the 21st letter of the Greek alphabet) and noted φc. The formula to estimate Cramér’s V is shown in Equation (8), where n stands for the number of observations in the contingency table, k stands for the number of columns in the table, and r stands for the number of rows.
V = \sqrt{\frac{\chi^2 / n}{min(k - 1, r - 1)}}(8)
To apply this formula in R, we already have all the necessary data from the χ2 test and the table on which it was performed. The χ2 value can be extracted from the chisq.test() function under the name $statistic, the number of observations can be obtained by running the sum() function on our contingency table, and the number of columns and rows can be obtained with the ncol() and nrow() functions respectively. The estimation of Cramér’s V in R is shown is lines 259 to 269 for our example test carried out earlier. The command is split up over multiple lines and indented for greater clarity, but could just as well be entered on a single line. The χ2 value is enclosed by the as.numeric() function on line 261 to prevent the name assigned to the value (“X-squared”) from being carried over to the resulting Cramér’s V value. You can test the lines below with and without the as.numeric() to see the difference.
The Cramér’s V can also be estimated more conveniently with the cramersV() function from the “lsr” package (Navarro, 2015), as shown in lines 270 to 273.
The traditional interpretation of effect size of Cramér’s V follows the demarcations proposed by Cohen (1988, 1992), which sets the values of 0.1, 0.3, and 0.5 as boundaries between small, medium, and large effects. More recently, Gignac & Szodorai (2016) have questioned the categorization by Cohen for being “impression-based” (2016, p. 75) and propose the thresholds of 0.1, 0.2, and 0.3 based on their meta-study of effect sizes. The different thresholds for effect size based on Cramér’s V are summarized in Table 4.
Table 4. Summary of effect size thresholds for Cramér’s V based on Cohen (1988, 1992) and Gignac & Szodorai (2016)
Effect size
Cramér’s V (Cohen)
Cramér’s V (Gignac & Szodorai)
Small
0.1
0.1
Medium
0.3
0.2
Large
0.5
0.3
As such, the effect of diatopic variation on word order production can be described as medium if one follows the original guidelines proposed by Cohen (1988, 1992), or as large if one follows the newer categorization by Gignac & Szodorai (2016). The p value obtained for the χ2 test also applies to the effect size, so that we can report a medium/large and highly significant effect.
For the t-test, the measure of effect is Cohen’s d. The formula to estimate Cohen’s d is shown in Equation (9), where μ1 and μ2 stand for the means of groups 1 and 2 respectively, and s stands for the pooled standard deviation, which is estimated separately in Equation (10). In this equation, n1 and n2 stand for the number of observations in each respective group, and s1 and s2 stand for the variance of each respective group.
In R, the number of observations in each group can be obtained via the length() function, and the variance for each group can be obtained via the var() function. In lines 274 to 303, which picks up on our test carried out earlier, we first save the speaker age values in two categorical groups (SVO vs VSO), based on which we can determine s and then d.
The effect size based on Cohen’s d is commonly interpreted with the thresholds of 0.2, 0.5, and 0.8 for small, medium, and large effects respectively (Cohen, 1988). Sawilowsky (2009) expands this categorization with the descriptors “very small”, “very large”, and “huge”, as summarised in Table 5.
Table 5. Effect size based on Cohen’s (1988) original categorization and the expansion proposed by Sawilowsky (2009)
Effect size
Cohen’s d
Reference
Very small
0.1
Sawilowsky (2009)
Small
0.2
Cohen (1988)
Medium
0.5
Cohen (1988)
Large
0.8
Cohen (1988)
Very large
1.2
Sawilowsky (2009)
Huge
2.0
Sawilowsky (2009)
As such, the effect of speaker age on word order production can be described as medium.
It is possible that multiple independent variables exert influence over a dependent variable. In such cases, performing separate tests for each independent/dependent variable combination may only tell part of the story. A more comprehensive approach is to use a Multivariate Analysis, i.e. a test that probes the influence of multiple independent variables. This will be demonstrated using the second data set, reading.csv. Just as with the previous data set esvio.csv, we import and inspect the data.
The reading data set contains data from a fictional reaction time experiment. Individual words are displayed on a screen, and respondents press a button after having read a given word. The time between the appearance of a word on the screen and the respondent pressing the button was recorded in milliseconds and is now stored under the statistical variable $ReactionTime. The words displayed on screen are classified according to two characteristics: 1. whether they are high- or low-frequency words, stored under $FrequencyClass, and 2. whether they are content or function words, stored under $WordClass.
An inspection of the data reveals a total of 800 tokens, equally split into high versus low frequency content and function words. What is noteworthy is the presence of a negative value in the summary of the numerical variable $ReactionTime. This should not be the case, as a respondent cannot have read a word and pressed the button before the word appeared on screen. This means that there is a problem with the data: either these isolated tokens were faultily recorded, or the entire data set is corrupted, perhaps by badly calibrated equipment. As this is a fictional example, we will simply remove the negative values, but in a real situation, the source of the problem should be investigated, and a decision on whether to discard the isolated data points or the entire data set should be made. For this reason, it is always a good idea to perform a test run prior to any experiment, and always inspect a data set when importing it into R.
To remove the negative reaction times, we use indexing, as introduced earlier during the introduction of vectors and matrices, but instead of specifying the index numbers of negative values, we exclude them with a condition. In the lines below, we only keep rows with a reaction time greater than zero.9 The newly created data frame reading.new only kept rows with positive values, which is confirmed upon inspection of the summary.
Now that the data set has been cleaned up, the analysis can proceed. We have two independent variables, $FrequencyClass and $WordClass, which can influence the dependent variable $ReactionTime.
Exercises
Practice the material introduced so far by analyzing the influence of each independent variable over the dependent variable.
Which test should you use? Describe the steps guiding your decision.
Carry out the tests and report your results.
Create plots illustrating your analyses. Which plot type should you use?
The multivariate analysis to be introduced here is called Linear Regression. The specific type of linear regression to be used depends on the type of the dependent variable. For numerical dependent variables, a Gaussian Linear Regression should be used. This is achieved with the lm() or glm() functions (short for “linear model” and “generalized linear model” respectively). If the dependent variable is a categorical variable with two levels, a Binomial Linear Regression should be used. For this, the glm() function can be used, for which the “family” parameter should be changed from the default value family=gaussian to family=binomial. Should the dependent variable be a categorical variable with more than two levels, a Multinomial Linear Regression should be used instead. The function multinom() from the “nnet” package (Venables & Ripley, 2002) can be used for this. What all these functions have in common is that they accept a formula in the same format, i.e. response ~predictor1 +predictor2 ..., where “response” stands for the dependent variable, and predictors for independent variables, which can be listed separated by + signs.
The concept of linear regression is to test how the dependent variable changes when one of the independent variables is changed. For numerical independent variables, the numerical value is increased by 1, and the effect that this change has on the dependent variable is observed. For categorical independent variables, the value is changed from one level to another, and the effect that this change has on the dependent variable is observed. For categorical variables, it is important to set a reference level, as by default, R orders the levels alphabetically, as shown in lines 347-350. Given that this default ordering is arbitrary, one should decide what levels should be considered to be the baseline for comparison, and relevel the variables accordingly. For example, let us set the type “high frequency function word” as our baseline in order to see how changing this to either a “low frequency function word” or a “high frequency content word” affects reaction times. We therefore need to relevel the $WordClass variable, as R automatically set “content” as the reference level given that C comes before F in the alphabet. Using the relevel() function, we define “function” as the new reference level in line 351.
Now that the reference levels have been set, we can define our linear regression model. As our dependent variable is numerical, we should use a Gaussian linear model, using either lm() or glm(), and save this model as a variable. We then obtain details on this model by using the summary() function.
When applied to a linear model, summary() generates a wealth of output. For our analysis, the most relevant part is the table shown in lines 364-370. The first row (line 366) shows the mean value of our dependent variable $ReactionTime when both independent variables are at their reference levels, i.e. $FrequencyClass=="high" and $WordClass=="function". This combination of all independent variables at their reference levels (or at the value 0 for numerical independent variables) is called the Intercept. The probability value given in the last column can be ignored for the intercept. For each following row, the values of the independent variables are changed in turn. For example, in the second row (line 367), the Estimate for the mean value, sometimes abbreviated as β, of the dependent variable $ReactionTime increases by 64.153 in comparison to the intercept when the value of the independent variable $FrequencyClass changes from “high” to “low”. In other words, the estimated mean reaction time becomes 290.845 milliseconds (226.692 + 64.153) when this change occurs. Therefore, subjects exhibit longer reaction times when faced with low frequency words. The Standard Error value is a measure of uncertainty of the estimate. This means that the actual mean may be in a range of ±6.817 milliseconds compared to the estimate of 64.153. The t value is measured by dividing the estimate by the standard error. The p value given in the last column applies to a H0 stating that that differences observed between the estimated mean and the intercept, as expressed by the t value, are due to chance, which in this case is extremely unlikely. In a similar vein, the next row (line 368) shows how the mean reaction time changes when the value of the variable $WordClass changes from “function” to “content” (NB: the variable $FrequencyClass is set back to its reference level “high”). The change of the variable $WordClass from “function” to “content” also causes slower reaction times, but to a lesser degree than was observed for $FrequencyClass.
In some cases, one has to wonder if the independent variables are truly independent. In our case, frequency and word class may actually be linked, as function words (such as determiners, conjunctions, or prepositions) tend to be more frequent than content words. To test this, we make an additional model that tests the Interaction between the independent variables. To achieve this, we replace any + character in the formula with a * character.
Compared to the table of the previous model (lines 364-370), the table of the new model (lines 385-392) contains an additional row (line 390) that estimates the mean value of the dependent variable ($ReactionTime) when both independent variables take on values other than reference levels at the same time. The value of -32.238 refers to the difference between the observed mean and the expected mean if there was no interaction between the independent variables whatsoever. This means that instead of mean reaction time of 329.513 milliseconds that would be expected if we simply added the separate estimates to the intercept (218.643 + 80.251 + 30.619), we instead estimate a mean reaction time of 297.275 milliseconds (329.513 - 32.238). The reported p value applies to the H0 stating there is no interaction between the independent variables, which in this case cannot be supported.
Reporting the results of a multivariate analysis can be done in the form of a table, for example as shown in Table 6.
Table 6. Binomial linear regression of the effect of frequency and word class on reading times
Value
Estimate
StE
t
p
(Intercept)
218.643
6.793
32.186
< 2e-16 ***
FrequencyClass: low
80.251
9.607
8.353
2.96e-16 ***
WordClass: content
30.619
9.619
3.183
0.00151 **
FrequencyClass: low * WordClass: content
-32.238
13.595
-2.371
0.01797 *
Additionally, we can also display the information in a plot. The lineplot.CI() function from the “sciplot” package (Morales, 2017) provides a convenient way to generate such plots. The function plots the dependent variable on the y-axis using a parameter called response. The independent variables can be entered under the parameters x.factor or group, depending on which independent variable should be represented on the x-axis, and which independent variable should be used to distinguish groups of data points. In lines 397-407, we define $WordClass as the x-axis variable and $FrequencyClass as the grouping variable, which yields Figure 11. In lines 408-418, we exchange the independent variables to produce Figure 12.
Figure 11. Line plot showing the effect of word class (x-axis) and frequency (grouping variable) on mean reaction timeFigure 12. Line plot showing the effect of frequency (x-axis) and word class (grouping variable) on mean reaction time
Figures 11 and 12 display the same information, but are organized differently. What both figures have in common is that the intercept (high frequency function word) is located on the bottom left. Any change to the intercept by modifying the value of any of the independent variables results in slower reaction times. The interaction between the two independent variables becomes clear, as the lack of any interaction should result in parallel lines, which is clearly not the case here. The change from function word to content word, which shows an effect for high frequency items, barely makes a difference for low frequency items, as seen by the almost horizontal line in Figure 11, as well as the merging of the two points in Figure 12. The bars around the individual points are called Confidence Intervals and correspond to the standard error values generated by the model.
The “ggplot2” package (Wickham, 2009) produces visually pleasing plots directly from data frames. The use of the package will be explained by recreating the plots produced so far.
The basic concept of “ggplot2” is to call the ggplot() function, in which the name of the statistical variables to be plotted are listed in the aes() function (short for aesthetics). To recreate the barplots in Figure 7, we do not need to create a contingency table as before, but can supply the names of statistical variables directly from the esvio data frame. The data frame and the statistical variables to be plotted are specified on line 423, and the type of plot is defined as a bar plot with the geom_bar() function on line 424. Notice how line 423 ends with a + character. This is to signal to R that the command sequence is not complete yet, which allows us to specify further “ggplot” functions, such as the plot type on line 424, and additional options such as custom labels (line 425), and a black and white theme rather than the default grey background (line 426). This produces the left plot in Figure 13. To produce a proportional plot (right plot of Figure 13), the parameter position = "fill" is added to geom_bar() (line 432). By default, this stretches the bar to fill the y-axis to a maximum value of 1. To change this “per 1” to “per cent”, the “scales” package (Wickham, 2016) provides a convenient percent_format() function which can be used to change the scale of the y-axis (line 434). In terms of colours, “ggplot” divides a colour spectrum into equal parts, which works well enough for a small set of levels, but becomes problematic when there are many categories and the colours are not distinct enough. You can define your own colour palette, for example as done in lines 429-430 with a colourblind-friendly palette (inspired by Okabe & Ito, 2008), which can then be used as a colour scheme for the plot (line 435).
Figure 13. Recreation of bar plots in Figure 7 with ggplot2
The main advantage of “ggplot2”, namely the ability to plot directly from a data frame, cannot be taken advantage of when we want to plot values that have been transformed (for example normalized frequencies from a corpus). This restriction also applies to the Pearson residuals we plotted in Figure 8. As the values for the Pearson residuals are not present in the esvio data frame, we need to create a contingency table as before (line 153) and run the chisq.test() to access the residual values under the name $residuals. As “ggplot2” accepts only data frames, we cannot use the table of Pearson residuals as is, but need to convert it to a data frame first. The melt() function from the “reshape2” package (Wickham, 2007) simplifies this process by turning the table into a data frame that is immediately usable with “ggplot2” (lines 440-449). In order to plot these values, we have to specify the parameter stat = "identity" on line 454 because by default, the geom_bar() function expects categorical variables only from which it counts its y-axis values. In this case, the y-axis values are already pre-computed, and the stat = "identity" parameter tells the function to simply take the values from the numerical variable assigned to the y parameter. The position = "dodge" has the same effect as the beside =TRUE parameter introduced for standard R graphics in line 178.
Figure 14. Recreation of the bar plot in Figure 8 with ggplot2
To recreate the density plot in Figure 9, we can assign the statistical variables to parameters just as before and simply change the plot type from bar plot to density plot (lines 463). However, as the fill parameter fills the drawn surface with colour (as its name implies), transparency should be set with alpha parameter (ranging from 0: entirely transparent, to 1: entirely opaque) so that one density curve does not hide the other. In line 463, we choose the value alpha =0.5 for halfway transparency. We may optionally supply our own colour scheme, as done in line 465. Here, we exclude the first value of our colourblind-friendly palette, which is grey and may therefore be hard to see against the default grey background, or even the grey gridlines should the black and white theme be chosen. In lines 466-473, we produce an alternate version of the same density plot with a few improvements. First, we use the color parameter instead of the fill parameter, so that the lines themselves are coloured rather than the surface they cover. Note how the name of the function used to define the colour scheme, scale_fill_manual(), matches the name of the parameter fill in lines 462 and 465, whereas the color parameter matches the function scale_color_manual() (lines 468 and 471). A further change we can make is to extend the range of the x-axis. By default, the x-axis corresponds to the range of the statistical variable assigned to the x parameter, which may cut off the ends of the density curves. We therefore manually specify new limits for the x-axis in line 472.
Figure 15. Recreation of the density plot in Figure 9 with ggplot2
To recreate the box plot in Figure 10, we specify statistical variables as before, with the exception that we supply the numerical variable $speaker_age as the parameter y, given that these numerical values should correspond to the y-axis. The type of plot is also different, as we want a box plot rather than a bar plot or a density plot.
Figure 16. Recreation of a box plot in Figure 10 in ggplot
In order to plot the line plots of the multivariate analysis in Figures 11 and 12, we use the geom_smooth() function and specify that we want to draw a line based on a linear model (line 480 or 485). The grouping variable is assigned to two parameters in line 479 or 484. The parameter group tells geom_smooth() how to split up the groups, while color defines how to colour the lines and draw the legend.
Figure 17. Recreation of the line plots in Figures 11 and 12 in ggplot2
It should be noted that plotting the results of a linear regression model is not the only way to visualize multivariate data. Drawing box plots separated by a grouping variable, as done in lines 487-490 to produce Figure 18, shows the interaction between the independent variables $FrequencyClass and $WorldClass in the same way as Figure 12 and the right-hand pane of Figure 17.
The concept of Literate Programming, introduced by Donald Knuth (1984, 1992), flips the usual hierarchy of code and comments. In literate programming, comments constitute the centrepiece and are written in a coherent manner much like in an essay, while the code is placed in snippets. This motivates one to clearly write down the how and why of the code, leading to a better readibility and documentation of the code.10
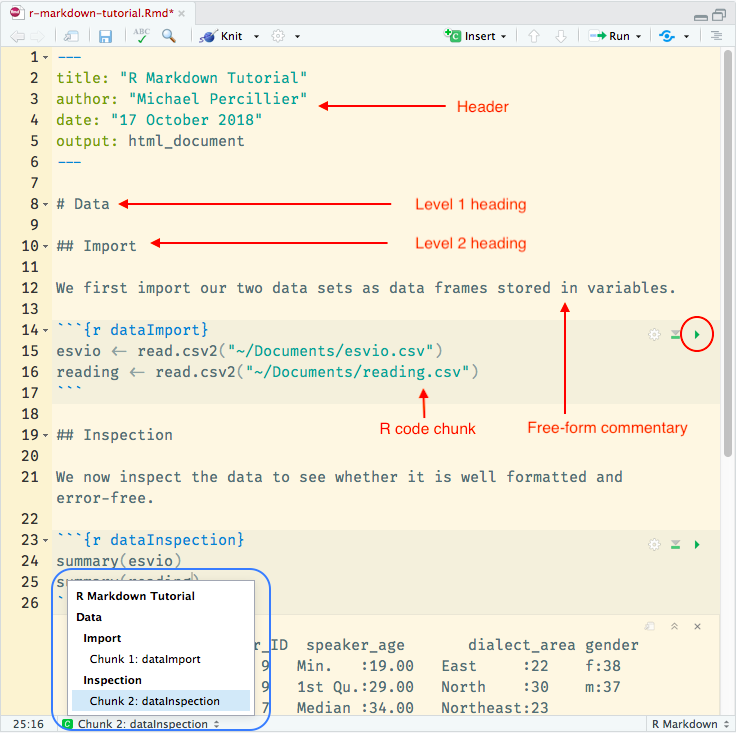
In RStudio, literate programming is implemented via the “rmarkdown” package (Allaire et al., 2018). To create a new R Markdown document, select the File > New File > R Markdown... option from the menu bar. The file that is generated contains some buffer text that explains the basic functions of R Markdown. R Markdown files use the .Rmd file suffix rather than the .R suffix used for regular R script files. The section at the very top that is enclosed by sets of three hyphens is the header, in which some metadata such as title, author, date, etc. can be specified. Unlike in regular R, lines beginning with a # character do not mark a commented line, but rather a heading, with the number of # characters signalling the level of the heading (up to six levels). Code commentary is to be entered as free text, and can even be formatted using Pandoc Markdown features, which include italics, bold, footnotes, citation management, and other features.11 The actual R code is to be included in designated code blocks, marked by sequences of three back ticks, which will be set in a contrasting background colour. For each code block, the programming language should be indicated in a set of curly brackets, and ideally also an identifying name (see line 497). Using headings and code chunk names consistently generates a navigation bar at the bottom of the code editor (see blue highlight box at the bottom of Figure 19).
To execute a code chunk, click on its green “play” symbol (highlighted by a red circle on the right hand side of Figure 19). Note that the symbol will not appear unless a programming language is specified in curly brackets for the chunk, which in our case should be R, signalled as r. The symbol located immediately to the left executes all preceding code chunks, which is useful to make sure all variables are up to date before executing the intended code chunk.
Figure 19. Commented screenshot of an R Markdown document
Several introductions to R for linguistics have appeared in recent years, such as Baayen (2008), Gries (2013), Gries (2017), Levshina (2015), or Schneider & Lauber (2019). The introduction by Field, Miles, & Field (2012), though not focused on linguistics, can be recommended for its highly approachable style. For an even more approachable introduction to statistics, told in the format of a graphic novel, see Field (2016).
The official ggplot2 website provides a brief introduction, as well as a wealth of useful links and a convenient cheat sheet. For a more comprehensive introduction, the website recommends chapters 3 (“Data visualisation”) and 28 (“Graphics for communication”) of Wickham & Grolemund (2016).
The RStudio website hosts an introductory tutorial to R Markdown. Xie, Allaire, & Grolemund (2018) offers a more detailed guide. Chapters 27, 29, and 30 of Wickham & Grolemund (2016) also cover R Markdown.
Allaire, J. J., Xie, Y., McPherson, J., Luraschi, J., Ushey, K., Atkins, A., … Chang, W. (2018). Rmarkdown: Dynamic Documents for R. Retrieved from https://CRAN.R-project.org/package=rmarkdown
Baayen, R. H. (2008). Analyzing Linguistic Data: A Pratical Introduction to Statistics Using R. Cambridge: Cambridge University Press.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences (2nd ed.). Hillsdale, N.J: L. Erlbaum Associates.
Field, A. (2016). An adventure in statistics: The reality enigma. Thousand Oaks, CA: Sage.
Field, A. P., Miles, J., & Field, Z. (2012). Discovering statistics using R. London: Sage.
Firth, J. R. (1957). Papers in Linguistics: 1934-1951. London: Oxford University Press.
Gignac, G. E., & Szodorai, E. T. (2016). Effect size guidelines for individual differences researchers. Personality and Individual Differences, 102, 74–78. doi:10.1016/j.paid.2016.06.069
Gries, S. T. (2013). Statistics for linguistics with R: A practical introduction (2nd ed.). Berlin: De Gruyter Mouton.
Gries, S. T. (2017). Quantitative corpus linguistics with R: A practical introduction (2nd ed.). New York: Routledge, Taylor & Francis Group.
Knuth, D. E. (1984). Literate Programming. The Computer Journal, 27(2), 97–111. doi:10.1093/comjnl/27.2.97
Knuth, D. E. (1992). Literate Programming. Stanford, CA: Stanford University Center for the Study of Language & Information.
Levshina, N. (2015). How to do Linguistics with R: Data exploration and statistical analysis. Amsterdam: John Benjamins Publishing Company. doi:10.1075/z.195
Murphy, K. R., & Myors, B. (1998). Statistical power analysis: A simple and general model for traditional and modern hypothesis tests. Mahwah, N.J.: L. Erlbaum Associates.
Navarro, D. (2015). Learning statistics with R: A tutorial for psychology students and other beginners. (Version 0.5). Adelaide, Australia: University of Adelaide. Retrieved from http://ua.edu.au/ccs/teaching/lsr
Okabe, M., & Ito, K. (2008). Color Universal Design (CUD) - How to make figures and presentations that are friendly to Colorblind people. Tokyo: University of Tokyo. Retrieved from http://jfly.iam.u-tokyo.ac.jp/color/
Plag, I., Dalton-Puffer, C., & Baayen, H. (1999). Morphological productivity across speech and writing. English Language and Linguistics, 3, 209–228.
R Core Team. (2018). R: A Language and Environment for Statistical Computing. Vienna, Austria: R Foundation for Statistical Computing. Retrieved from https://www.R-project.org/
Sarkar, D. (2008). Lattice: Multivariate Data Visualization with R. New York: Springer. Retrieved from http://lmdvr.r-forge.r-project.org
Sawilowsky, S. S. (2009). New Effect Size Rules of Thumb. Journal of Modern Applied Statistical Methods, 8(2), 597–599. doi:10.22237/jmasm/1257035100
Venables, W. N., & Ripley, B. D. (2002). Modern Applied Statistics with S (4th ed.). New York: Springer. Retrieved from http://www.stats.ox.ac.uk/pub/MASS4
Wickham, H. (2007). Reshaping Data with the reshape Package. Journal of Statistical Software, 21(12). doi:10.18637/jss.v021.i12
Wickham, H. (2009). Ggplot2: Elegant Graphics for Data Analysis. New York: Springer. Retrieved from http://ggplot2.org
Wickham, H., & Grolemund, G. (2016). R for data science: Import, tidy, transform, visualize, and model data. Sebastopol, CA: O’Reilly. Retrieved from http://r4ds.had.co.nz
Wilkinson, L., & Task Force on Statistical Inference. (1999). Statistical methods in psychology journals: Guidelines and explanations. American Psychologist, 54(8), 594–604. doi:10.1037/0003-066X.54.8.594
Xie, Y., Allaire, J. J., & Grolemund, G. (2018). R Markdown: The definitive guide. Boca Raton: Taylor & Francis, CRC Press. Retrieved from https://bookdown.org/yihui/rmarkdown/
Variables are stored for the current session only. When quitting R or RStudio, the user is asked whether to save the workspace. By choosing “yes”, variables can be restored during the next session. While this may seem like a good idea at first glance, I strongly advise against this, as variables containing values from older data may be mixed with variables containing values from newer data, potentially leading to falsified results. Instead, I recommend restoring variables from commands stored in a script file, which also forces one to document how each variable is created. When prompted to save the workspace, either consistently decline, or better yet, go to the preferences of R or RStudio and change the setting “Save workspace to .RData on exit” from the default value “Ask” to “Never”.↩
Both data sets were created by David Lorenz (University of Rostock).↩
The by() function is a more convenient version of the tapply() function, which applies a given function to each group of values defined by the levels of a given categorical variable. As the mechanism of tapply() is not immediately apparent from its name, by() may be easier to remember for R novices. Both functions follow the same principle, with the difference that their outputs are formatted differently.↩
Sometimes called Student’s t-test after William Sealy Gosset’s pseudonym “Student”.↩
Do not forget to cite any package you use in addition to citing R. The citation() function returns details on how to cite R. Specifying a package name, e.g. citation("lattice"), will provide details on how to cite this specific package.↩
Notice how the prompt character changes from > to + in line 230. This happens because the bracket pair of the densityplot() function has not been closed on the previous line. Therefore, the R console expects further input and will mark any new line with a + until the bracket pair is closed. Leaving bracket pairs open can be used on purpose to write long an complicated commands over multiple lines for greater clarity.↩
The e character used in the p value of the SVO group stands for “exponent”. The value 5.39e-05 therefore represents 5.39×10-5, i.e. 0.0000539. R switches to this scientific notation whenever a value is considered too large or too small to be written out in full.↩
Otherwise, the test could be run with the t.test() function, as for example in t.test(speaker_age ~word_order, esvio).↩
Unless one considers it possible to read a word and press a button instantaneously, or at least within a duration below the measurable time unit of one millisecond, in which case the condition can be set as reading$ReactionTime >=0, where the operator >= stands for “≥” (“greater or equal than”).↩
You can even generate reports in the PDF, HTML, or Word formats by clicking on the “Knit” button.↩